tcmalloc小记
原文:https://google.github.io/tcmalloc/design.html
之前尝试过探索一下golang的内存分配机制,但是由于其太过于庞大,个人积累也不足,就先放弃了。后来想起来它跟tcmalloc的分配方式很像,所以就单独抽时间看了下tcmalloc的设计思路。
这篇几乎是原文的翻译篇,可能会加入一些个人理解。
tcmalloc的特性
- 大多数的分配和释放内存都是无竞态的,对于多线程程序来说更加友好。
- 被释放的内存可以给不同大小的对象进行复用,或者交还给操作系统,在内存使用上更加灵活。
- 分配相同大小对象的page,从而节省用于管理小对象的内存开销。
- 提供了解当前内存使用情况的能力,并且采样的开销较小。
概览
下面这张图是tcmalloc内部的概览图。
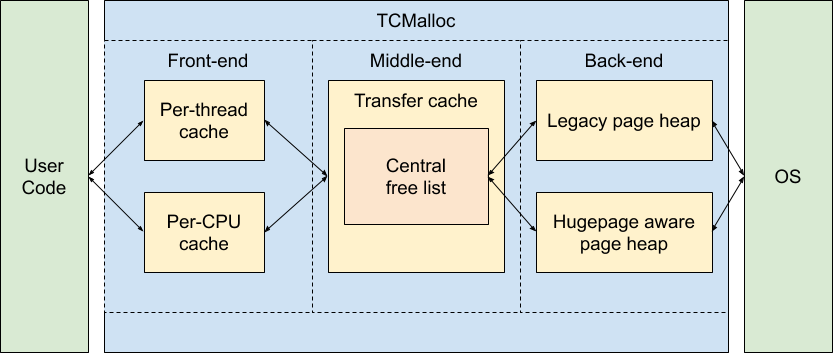
意思是可以将tcmalloc大致分为三个层次:
- front-end:提供线程或者cpu级别的cache,这是最快的分配对象方式。
- middle-end:负责填充front-end的cache。
- back-end:负责向操作系统申请更多的可用内存。
就这么简单一看的话,tcmalloc似乎就是利用了缓存以及线程隔离的思想去加快分配内存。
front-end要么是运行在per-cpu的模式或者传统的per-thread模式,以及back-end要么支持传统页堆或者大页堆。
front-end
front-end管理cache,这个cache的里面是待分配内存块,cache每次只会被一个线程访问,因此不需要加锁,分配和释放内存都非常快。
如果外界向front-end请求的内存大小对应的cache为空,那么front-end就会向middle-end去请求一批可用内存去填充cache。middle-cache由CentralFreeList和TransferCache组成。
如果外界向front-end请求的内存大于front-end最大的cache,或者middle-end已经耗尽,那么就会找back-end分配这个大内存块,或者请求填充middle-end。back-end也称为PageHeap页堆。
之前说到front-end的两种模式,分别是per-thread和per-cpu,因为现代大型程序通常包含很多线程,每个线程都要cache,就会导致front-end整体内存占用很大,若要降低front-end的整体内存占用,那么每个线程的cache又会变得太小,导致cache频繁耗尽或者溢出。回想一下tcmalloc要弄per-thread cache的原因只是为了降低并发锁冲突,但现代计算机上如果多个线程运行在同一个cpu上,这些线程实际上是线性交替执行,因此tcmalloc支持了per-cpu的模式,从而降低内存占用的同时又能保证降低并发冲突。
分配小对象和大对象
小对象会由front-end来负责映射到60到80个大小类别中,比如分配一个12字节的对象属于16字节的大小类别。但是如果分配的内存太大,就会由back-end来直接负责此次分配,这种对象的大小与tcmalloc页大小对齐。
原文还说了一些关于小对象内存分配对齐的事情,这里跳过。
释放内存
关于内存的释放这块感觉还是挺复杂的。
首先,如果释放的内存大小是编译时未知的,tcmalloc就要去查找pagemap。如果释放的是小对象,就会被归还到front-end的cache中,否则就会被归还到back-end的页堆中。
per-cpu模式
在这个模式中,front-end管理着一大块内存(称为slab)
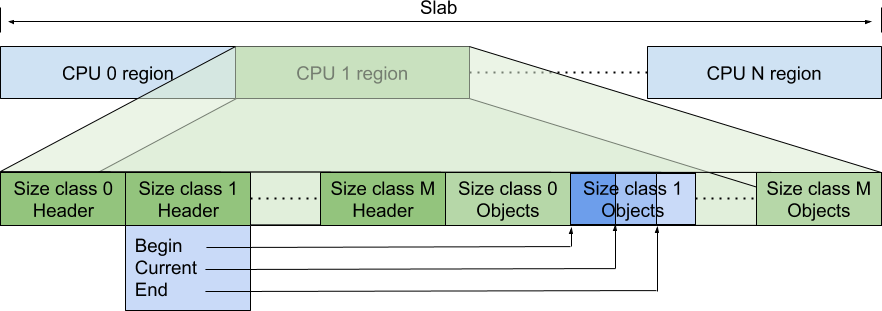
一图胜千言,slab被分为多个cpu块交给不同的cpu管理,我们将cpu块称为cpu本地缓存。本地缓存中的左边存储元数据,右边存储指向可用对象的指针数组。
元数据中有三种指针,分别指向对应大小类数组中的开始位置、当前分配到的位置、当前最大位置。另外,还有一个全局的“静态最大容量”,限制了当前最大位置减去数组开始位置不能大于这个“静态最大容量”。虽然没看过内部实现,但盲猜这个静态最大容量是硬编码的,并且“开始位置指针”和“当前最大位置指针”在整个cpu块上是动态变化的,目的是尽量高效地提高内存利用率。
对象都从本地缓存中获取或者归还,当获取时如果本地缓存不够用就会找middle-end拿,当归还的时候如果本地缓存溢出则溢出到middle-end中。
当某个大小类别的对象已经分配完,tcmalloc会尝试增大该大小类别的容量,直到达到该大小类别的静态最大容量或者整个cache的最大容量。为了增加容量,该大小类别甚至可以从同一个cpu块的其它大小类别中“偷”容量。
front-end限制的是单个cpu本地缓存的大小,那么如果机器的cpu越多,front-end就占用越多内存。为了节省内存,当程序不再使用某个cpu时,tcmalloc支持释放该cpu缓存中的内存。
rseq
tcmalloc的per-cpu模式依赖于linux的rseq系统调用。rseq可以理解成原子指令序列,如果这个指令序列执行到一半发生了上下文切换,那么下一次会重新从头开始执行。该序列要么不间断地完成,要么反复重新启动,直到不间断地完成,这个过程是不需要锁的,从而避免了序列的争用。
那么rseq对于per-cpu模式的意义就在于,在无需使用锁的情况下就读写per-cpu数组的元素。
这部分更具体的设计参考https://google.github.io/tcmalloc/rseq.html
per-thread模式
在这个模式中,每个线程都有自己的本地缓存。每个本地缓存中的数据结构组织如图所示,每个大小类的空闲对象用单链表进行组织。
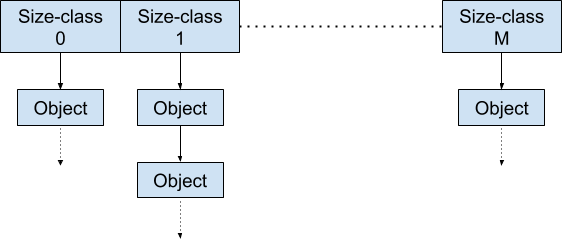
当线程结束的时候,该线程的本地缓存归还给middle-end。
front-end运行时动态扩缩容
这个小节介绍了front-end在运行时的内存占用不是一成不变的,而是会根据实际情况发生大小变化,涉及到调优的时候可能可以看一下:https://google.github.io/tcmalloc/design.html#runtime-sizing-of-front-end-caches
middle-end
middle-end负责解耦前后端,包括给front-end提供内存以及向后端归还内存。在middle-end中,每个大小类内存管理由一个传输缓存(transfer cache)和一个中央空闲链表(central freelist)管理。