nsq阅读(1)——概述
基于nsq v1.3.0
简介
NSQ是类似kafka、rabbitmq那样的消息队列系统,关于他怎么高性能,怎么好上手这些都不必多说,都是吹逼。这篇主要介绍一下nsq的整个大致架构,建立一个概念,方便后续的源码分析有迹可循。
架构
NSQ由三个守护进程组成:
- nsqd:接收、排队、分发消息
- nsqlookupd:管理拓扑,提供最终一致的服务发现
- nsqadmin:nsq的管理员界面
数据流
nsq数据流的数据流用图表示如下,这里的channel,有点类似kakfa的一个消费者组,一个channel对应一个消费者组。其他的不必再用文字多说,一图胜千言,更何况是个动图。
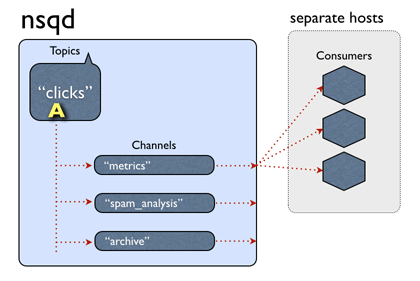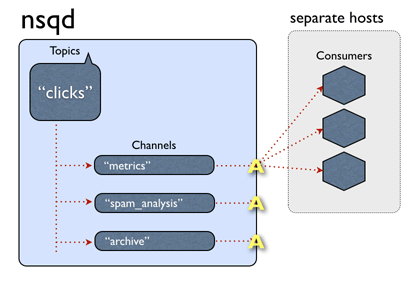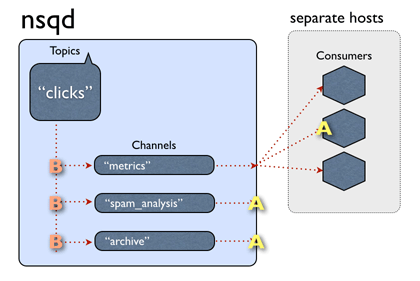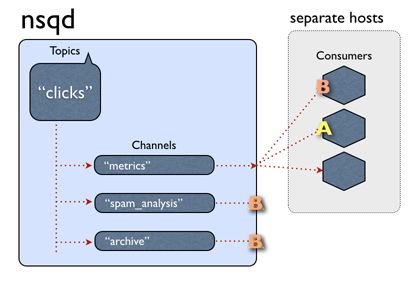
关于数据的存储方面,不是像kafka那样的存储一份+维护多个偏移量,官方说topic和channel都是各自独立维护数据的,目测更像rabbitmq那种,在做多播的时候,每个队列都存一份相同的数据。
消息传递保证
nsq保证消息至少消费一次,消费方要做好幂等。nsq投递消息给消费者的同时也临时保存在本地内存中,当消费者响应失败或者没有响应给nsq导致超时,nsq会重新投递消息。但如果nsq发生宕机,未刷盘的消息全部丢失。
nsq是内存型mq,磁盘只是用来存放内存队列溢出的数据,通过mem-queue-size参数控制单个队列在内存中的最大消息数。如果设为0的话,相当于所有消息持久化到磁盘,一定程度上避免nsq宕机丢失内存中的数据。
还有一种特殊队列,以#ephemeral为结尾来命名,这种队列在内存的消息超出mem-queue-size之后,会直接丢弃溢出的消息。
topic和channel
nsq中的topic和channel的概念在上面动图已经展现的淋漓尽致。这里说一下在内部是怎么实现的。nsq是用go语言实现的,go中带缓冲的chan刚好就满足了mem-queue-size这个参数的需求,chan的缓冲大小等于mem-queue-size。当生产者发消息到chan中,消费消息的时候,由于消息要copy到与topic绑定的每个channel,对此,nsq又开了个三个协程来处理:
router协程:读取chan中的消息,存储到队列中(内存或磁盘)messagePump协程:将消息拷贝并发布到channelsDiskQueue协程:负责IO
另外,每个channel还维护了两个按时间排序的优先队列,负责延时消息和未完成的消息。
运行nsq
前面说了那么多,或许都不如跑一把来得清晰。我们来运行一下nsq。
第一步:安装nsq。可以本地、docker、build源码等方式运行,为了简单这里直接在本机安装nsq(mac环境):
1
brew install nsq
安装完成后,nsq附带的几个命令行工具可以直接使用,对应于源码apps目录下:
第二步:启动守护进程。命令行运行nsqd和nsq_to_file,后者是用来将topic里的消息输出到本地文件,类似的还有nsq_to_http,将消息输出到自定义的http webhook:
1
2
3
4
5
# 运行nsqd
nsqd
# 运行nsq_to_file
nsq_to_file --topic test_topic --channel test_channel --nsqd-tcp-address 127.0.0.1:4150 -output-dir .
第三步:生产消息。向nsqd开放的http api发送消息:
1
curl -d "test message" "http://127.0.0.1:4151/pub?topic=test_topic"
打开文件就会看到内容(多执行几次curl):
1
2
3
test message
test message
test message
在实际生产中只需要运行nsqXXXd这些守护进程就行,至于nsq_to_xxx只是用来跑着玩的,查看源码就知道他们其实是nsq consumer,消费行为是将消息输出到文件或者http webhook中。