kafka源码阅读(3)-日志的增删改查
基于开源 kafka 2.5 版本。
如无特殊说明,文中代码片段将删除 debug 信息、异常触发、英文注释等代码,以便观看核心代码
本篇将继续深入研究 Log 的一些常见操作。
LeaderEpoch
在开始讲解日志之前,我觉得有必要先研究一下 LeaderEpoch 这个经常在代码中出现的东西。
上一篇有稍微提到 HM(high watermark,高水位)的概念,它的作用是为了保证分区副本之间的对外一致性,即高水位之前的偏移量才算是真正被提交偏移量。但是在 KIP-101 中提出了这种同步方法会将不必要数据截断导致效率低下,甚至会导致副本数据不一致的问题,最后引入 leader epoch 来替代 HM 来解决这些问题。
关于 HW 带来的问题查阅 KIP-101 即可,我们这里重点关注 leader epoch 的定义以及相应的一些代码实现。首先根据文档有如下定义:
- leader epoch 是一个单调递增整数,表示当前领导者的任期
- leader epoch start offset 是一个该领导者任期内的第一个偏移量
- leader epoch sequence file 是记录了所有 leader epoch => start offset 映射的文件,每个副本都维护了一份
- leader epoch request 是 follower 向 leader 发送的请求,follower 告诉 leader 它目前知道的最后任期,leader 返回该任期的最后一个偏移量的下一个偏移量,follower 会将该任期内超出该偏移量的消息截断以与 leader 保持一致
可以看到 follower 不再是根据 HW 进行偏移量截断,而是通过这份 epoch => offset 的映射表来截断。然后我们重新审视一下 leader epoch 是如何解决 HW 可能导致的问题的:
- 首先是第一个场景,follower 宕机恢复后如何避免不必要的数据截断。如下图所示,当 A 发生宕机重启之后,B 告知 A 当前任期 LE0 的偏移量上界为 2,那么偏移量为 2 之前的消息都不会被截断。之后 B 宕机,A 成为 leader,此时任期也正确递增变为 LE1,之后新增的消息所属任期都为 LE1。如果使用原先 HW 的方案,那么 A 的 m2 将会被不必要地截断。
另外,HW 的方案中,就算不直接将 m2 截断,而是像 leader epoch 那样先问 leader,但是也避免不了下面场景 2 带来的的问题。
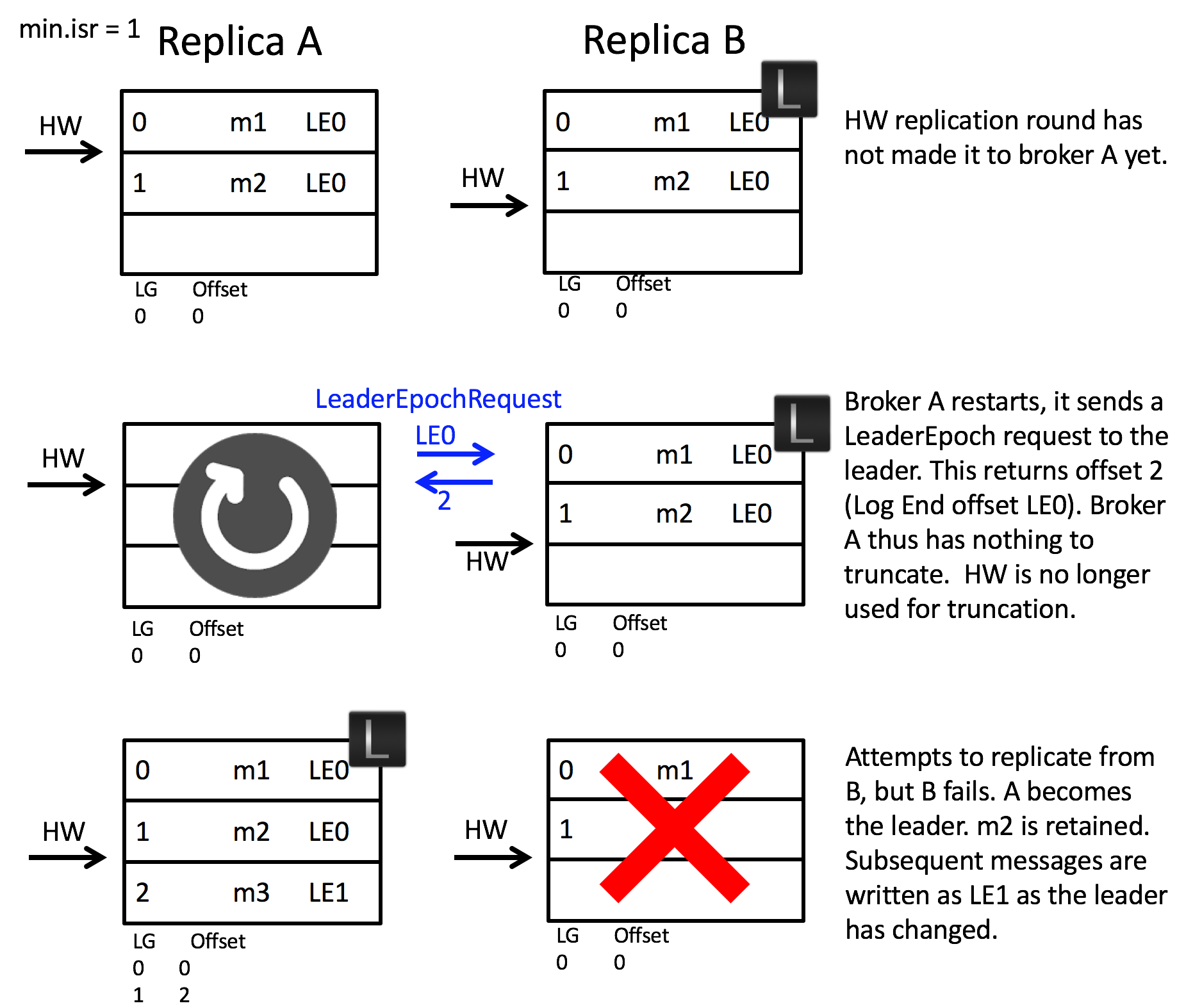
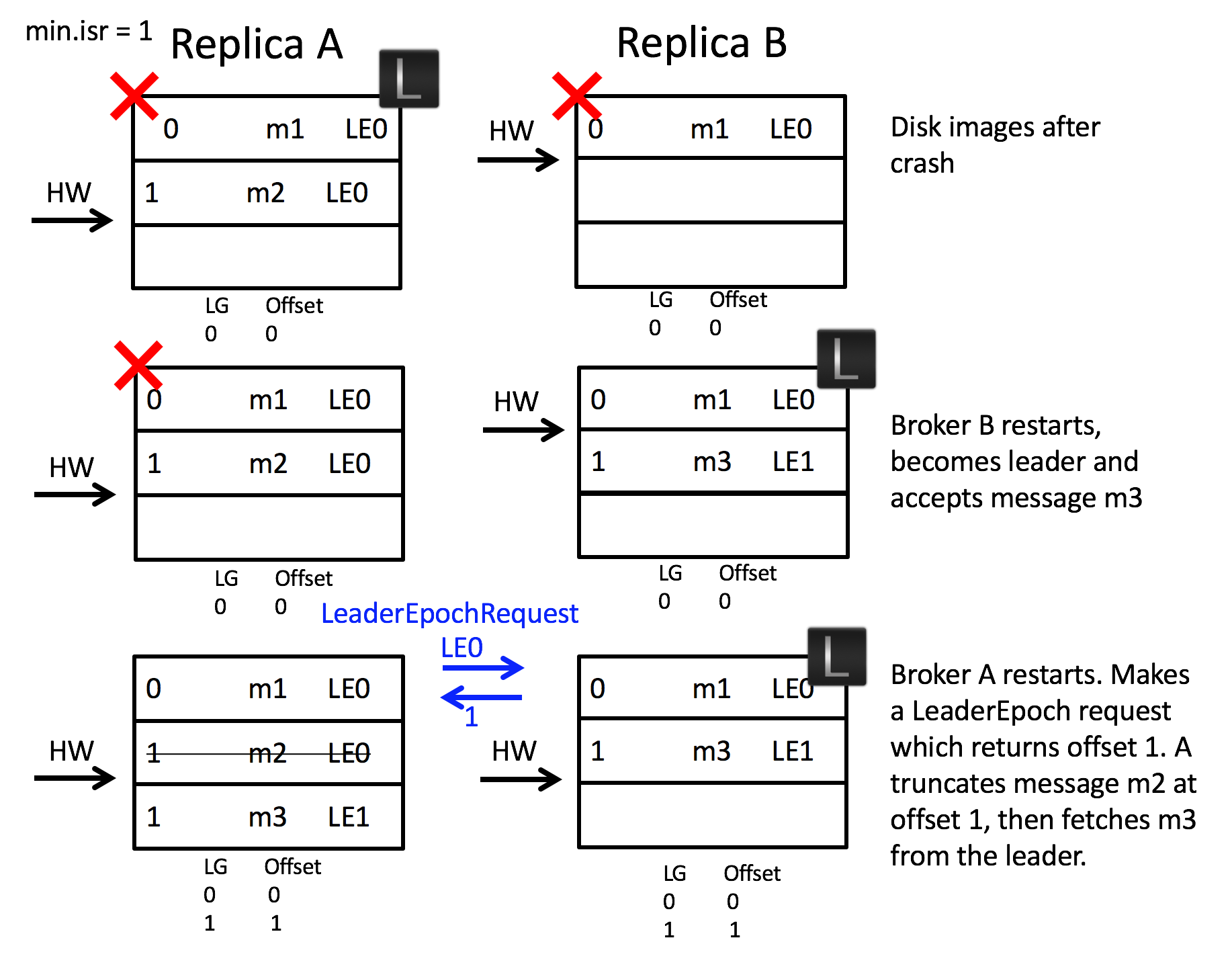
- 再来看第二个场景,如何避免副本数据不一致的情况。如下图所示,A 和 B 同时宕机,随后 B 先重启了,但由于消息落盘是异步的,此时 B 的硬盘中本应该存在的消息 m2 由于未落盘而丢失,并且 B 当上了 leader 并开始写入新的消息 m3。随后 A 重启并得知当前已知任期 LE0 的偏移量上界为 1,因此 A 会把任期为 LE0 并且偏移量大于等于 1 的消息截断,以与 leader B 保持一致。如果使用原先 HW 的方案,由于 HW 没有任期的区分,A 和 B 会被认为是一致的,因为他们的 HW 都在偏移量 1 这里,但实际上 A 在偏移量 1 处的消息是 m2,而 B 则是 m3,产生了比上面“错误的截断”更为严重的“副本数据不一致”问题。
leader epoch 的代码是LeaderEpochFileCache这个类,其实就是 leader epoch file 这个文件的内存缓存,仅此而已。里面的操作无非就是新增 leader epoch 映射、截断非法 leader epoch 等,核心方法只有 endOffsetFor,之后会遇到。
总而言之,leader epoch 协议的引入就是为了解决 high watermark 在副本同步时所导致的数据丢失、副本数据不同步等问题,大概知道它在干什么即可。
日志段管理
在 Log 类中,日志段保存在segments这个 map 中,日志段管理无非就是增删改查。“增”和“改”操作比较简单,只是更新segments而已,比如新增一个日志段:
1
def addSegment(segment: LogSegment): LogSegment = this.segments.put(segment.baseOffset, segment)
而“查”则是利用了 map 的一些现成方法,比如:
1
2
segments.firstEntry
segments.lastEntry
这里所谓删除是根据运行策略自动清除某些日志段,分别有两个重载方法 deleteOldSegments 去删除日志。首先是一个无参的版本,这个方法是被外部的 LogCleaner和LogManager调用的,这个方法比较直观,不多说:
1
2
3
4
5
6
7
8
9
def deleteOldSegments(): Int = {
if (config.delete) {
// 如果开启了自动清除,则删除过期日志、大小超出的日志、logStartOffset之前的日志
deleteRetentionMsBreachedSegments() + deleteRetentionSizeBreachedSegments() + deleteLogStartOffsetBreachedSegments()
} else {
// 否则只删除logStartOffset之前的日志
deleteLogStartOffsetBreachedSegments()
}
}
其中deleteXXXBreachedSegments分别对应三个删除策略,并且最终会调用下面这个带参的 deleteOldSegments。
1
2
3
4
5
6
7
8
9
// 从最老的日志开始,删除符合条件的日志
private def deleteOldSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean, reason: String): Int = {
lock synchronized {
// 筛选出被删除的日志段集合
val deletable = deletableSegments(predicate)
// 删除
deleteSegments(deletable)
}
}
我们重点分析 deletableSegments 和 deleteSegments 这两个方法,看源码的话,一定要看方法注释,这里注释已经说得非常清楚,这里我把核心部分翻译一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 从最老的日志开始遍历,遇到符合predict条件的就删除,一旦不符合就返回。
// 日志段除了要符合predict外,日志段的最后一个偏移量必须 < highWatermark,因为logStartOffset必须 <= highWatermark
private def deletableSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean): Iterable[LogSegment] = {
if (segments.isEmpty) {
Seq.empty
} else {
val deletable = ArrayBuffer.empty[LogSegment]
var segmentEntry = segments.firstEntry
while (segmentEntry != null) {
val segment = segmentEntry.getValue
val nextSegmentEntry = segments.higherEntry(segmentEntry.getKey)
val (nextSegment, upperBoundOffset, isLastSegmentAndEmpty) = if (nextSegmentEntry != null)
(nextSegmentEntry.getValue, nextSegmentEntry.getValue.baseOffset, false)
else
(null, logEndOffset, segment.size == 0)
if (highWatermark >= upperBoundOffset && predicate(segment, Option(nextSegment)) && !isLastSegmentAndEmpty) {
deletable += segment
segmentEntry = nextSegmentEntry
} else {
segmentEntry = null
}
}
deletable
}
}
接着看删除操作deleteSegments,其中的roll方法比较复杂,先忽略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
private def deleteSegments(deletable: Iterable[LogSegment]): Int = {
maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") {
val numToDelete = deletable.size
if (numToDelete > 0) {
if (segments.size == numToDelete)
roll()
lock synchronized {
// 确保日志没被关闭,以进行下面的IO操作
checkIfMemoryMappedBufferClosed()
// 删除日志段
removeAndDeleteSegments(deletable, asyncDelete = true)
// 更新logStartOffset
maybeIncrementLogStartOffset(segments.firstEntry.getValue.baseOffset)
}
}
numToDelete
}
}
// 删除步骤:
// 1. 删除日志段在segments成员中的键值对
// 2. 将日志和索引文件加上.deleted后缀(重点注意这里)
// 3. 根据asyncDelete,异步或马上删除文件
private def removeAndDeleteSegments(segments: Iterable[LogSegment], asyncDelete: Boolean): Unit = {
lock synchronized {
val toDelete = segments.toList
toDelete.foreach { segment =>
this.segments.remove(segment.baseOffset)
}
deleteSegmentFiles(toDelete, asyncDelete)
}
}
// 执行日志段文件删除操作
private def deleteSegmentFiles(segments: Iterable[LogSegment], asyncDelete: Boolean): Unit = {
// 日志和索引文件加上.deleted后缀
segments.foreach(_.changeFileSuffixes("", Log.DeletedFileSuffix))
def deleteSegments(): Unit = {
info(s"Deleting segments $segments")
maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") {
segments.foreach(_.deleteIfExists())
}
}
if (asyncDelete) {
// 异步删除
scheduler.schedule("delete-file", () => deleteSegments, delay = config.fileDeleteDelayMs)
} else {
// 同步删除
deleteSegments()
}
}
最后我们回头看下roll方法,这个方法用于日志切分,所谓切分就是当当前日志段满了之后,就关闭当前日志段并创建下一个日志段。(类似的概念也可以在 linux 的 logrotate 命令中找到):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
def roll(expectedNextOffset: Option[Long] = None): LogSegment = {
maybeHandleIOException(s"Error while rolling log segment for $topicPartition in dir ${dir.getParent}") {
lock synchronized {
checkIfMemoryMappedBufferClosed()
val newOffset = math.max(expectedNextOffset.getOrElse(0L), logEndOffset)
val logFile = Log.logFile(dir, newOffset)
if (segments.containsKey(newOffset)) {
// 新日志段已经存在(这里源码中有一个判断为了解决某个偶发bug,这里简略成直接抛异常)
throw new KafkaException(...)
} else if (!segments.isEmpty && newOffset < activeSegment.baseOffset) {
// 新日志段的偏移量应该大于当前日志段的偏移量
throw new KafkaException(...)
} else {
// 做一些清理工作,将当前日志段设置为非当前日志段
val offsetIdxFile = offsetIndexFile(dir, newOffset)
val timeIdxFile = timeIndexFile(dir, newOffset)
val txnIdxFile = transactionIndexFile(dir, newOffset)
for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if file.exists) {
warn(s"Newly rolled segment file ${file.getAbsolutePath} already exists; deleting it first")
Files.delete(file.toPath)
}
Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())
}
// 事务相关,忽略..
producerStateManager.updateMapEndOffset(newOffset)
producerStateManager.takeSnapshot()
// 创建新日志段
val segment = LogSegment.open(dir,
baseOffset = newOffset,
config,
time = time,
fileAlreadyExists = false,
initFileSize = initFileSize,
preallocate = config.preallocate)
addSegment(segment)
// 更新LEO
updateLogEndOffset(nextOffsetMetadata.messageOffset)
// 刷新老日志段
scheduler.schedule("flush-log", () => flush(newOffset), delay = 0L)
// 返回新日志段
segment
}
}
}
新增消息
Log 类的append方法用于新增一批消息到日志中,并且给消息分配偏移量,这个方法非常长,下面通过注释逐步分析,最后给出总结。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
private def append(
// 待新增的消息
records: MemoryRecords,
// 消息的来源,分别有:leader、coordinator、client,区别消息来源是为了对消息进行不同程度的合法性校验以提升效率
origin: AppendOrigin,
// 同上,用来校验合法性
interBrokerProtocolVersion: ApiVersion,
// 如果是leader则是true,即由leader分配消息偏移量
assignOffsets: Boolean,
// 这批消息所属的leaderEpoch
leaderEpoch: Int
): LogAppendInfo = {
maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") {
// 校验消息合法性,然后返回这批消息的元信息(比如消息数,第一条消息偏移量)
val appendInfo = analyzeAndValidateRecords(records, origin)
if (appendInfo.shallowCount == 0)
return appendInfo
// 截断这批消息中的非法批次及之后的消息
var validRecords = trimInvalidBytes(records, appendInfo)
lock synchronized {
checkIfMemoryMappedBufferClosed()
if (assignOffsets) {
// 为这批消息分配偏移量,第一个偏移量为当前日志的LEO
val offset = new LongRef(nextOffsetMetadata.messageOffset)
appendInfo.firstOffset = Some(offset.value)
val now = time.milliseconds
val validateAndOffsetAssignResult = try {
// 进一步检查消息合法性并且分配偏移量
LogValidator.validateMessagesAndAssignOffsets(validRecords,
topicPartition,
offset,
time,
now,
appendInfo.sourceCodec,
appendInfo.targetCodec,
config.compact,
config.messageFormatVersion.recordVersion.value,
config.messageTimestampType,
config.messageTimestampDifferenceMaxMs,
leaderEpoch,
origin,
interBrokerProtocolVersion,
brokerTopicStats)
} catch {
case e: IOException =>
throw new KafkaException(s"Error validating messages while appending to log $name", e)
}
// 更新appendInfo
validRecords = validateAndOffsetAssignResult.validatedRecords
appendInfo.maxTimestamp = validateAndOffsetAssignResult.maxTimestamp
appendInfo.offsetOfMaxTimestamp = validateAndOffsetAssignResult.shallowOffsetOfMaxTimestamp
appendInfo.lastOffset = offset.value - 1
appendInfo.recordConversionStats = validateAndOffsetAssignResult.recordConversionStats
if (config.messageTimestampType == TimestampType.LOG_APPEND_TIME)
appendInfo.logAppendTime = now
// 消息可能因为压缩或格式转换,而大小发生变动。因此重新检查大小确保不超过限制
if (validateAndOffsetAssignResult.messageSizeMaybeChanged) {
for (batch <- validRecords.batches.asScala) {
if (batch.sizeInBytes > config.maxMessageSize) {
brokerTopicStats.topicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes)
brokerTopicStats.allTopicsStats.bytesRejectedRate.mark(records.sizeInBytes)
throw new RecordTooLargeException(s"Message batch size is ${batch.sizeInBytes} bytes in append to" +
s"partition $topicPartition which exceeds the maximum configured size of ${config.maxMessageSize}.")
}
}
}
} else {
// 不需要为消息分配偏移量,检查偏移量是否单调递增
if (!appendInfo.offsetsMonotonic)
throw new OffsetsOutOfOrderException(s"Out of order offsets found in append to $topicPartition: " +
records.records.asScala.map(_.offset))
// 消息偏移量小于LEO,抛异常
if (appendInfo.firstOrLastOffsetOfFirstBatch < nextOffsetMetadata.messageOffset) {
val firstOffset = appendInfo.firstOffset match {
case Some(offset) => offset
case None => records.batches.asScala.head.baseOffset()
}
val firstOrLast = if (appendInfo.firstOffset.isDefined) "First offset" else "Last offset of the first batch"
throw new UnexpectedAppendOffsetException(
s"Unexpected offset in append to $topicPartition. $firstOrLast " +
s"${appendInfo.firstOrLastOffsetOfFirstBatch} is less than the next offset ${nextOffsetMetadata.messageOffset}. " +
s"First 10 offsets in append: ${records.records.asScala.take(10).map(_.offset)}, last offset in" +
s" append: ${appendInfo.lastOffset}. Log start offset = $logStartOffset",
firstOffset, appendInfo.lastOffset)
}
}
// 此时,消息已经分配了偏移量,更新leader epoch缓存
validRecords.batches.asScala.foreach { batch =>
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) {
maybeAssignEpochStartOffset(batch.partitionLeaderEpoch, batch.baseOffset)
} else {
...
}
}
// 确保这批消息大小不超过日志段大小限制
if (validRecords.sizeInBytes > config.segmentSize) {
throw new RecordBatchTooLargeException(s"Message batch size is ${validRecords.sizeInBytes} bytes in append " +
s"to partition $topicPartition, which exceeds the maximum configured segment size of ${config.segmentSize}.")
}
// 切分日志段
// 只有发生以下三种情况之一会发生切分:
// 1. 日志段满了
// 2. 日志段的索引满了
// 3. 自从日志段的第一条消息的时间戳开始,已经过了maxTime
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
val logOffsetMetadata = LogOffsetMetadata(
messageOffset = appendInfo.firstOrLastOffsetOfFirstBatch,
segmentBaseOffset = segment.baseOffset,
relativePositionInSegment = segment.size)
// 事务相关,忽略...
val (updatedProducers, completedTxns, maybeDuplicate) = analyzeAndValidateProducerState(
logOffsetMetadata, validRecords, origin)
maybeDuplicate.foreach { duplicate =>
appendInfo.firstOffset = Some(duplicate.firstOffset)
appendInfo.lastOffset = duplicate.lastOffset
appendInfo.logAppendTime = duplicate.timestamp
appendInfo.logStartOffset = logStartOffset
return appendInfo
}
// 将消息新增到当前日志段,这里执行真正的写入操作
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// 更新LEO
updateLogEndOffset(appendInfo.lastOffset + 1)
// 事务相关,忽略...
for (producerAppendInfo <- updatedProducers.values) {
producerStateManager.update(producerAppendInfo)
}
for (completedTxn <- completedTxns) {
val lastStableOffset = producerStateManager.lastStableOffset(completedTxn)
segment.updateTxnIndex(completedTxn, lastStableOffset)
producerStateManager.completeTxn(completedTxn)
}
producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1)
// update the first unstable offset (which is used to compute LSO)
maybeIncrementFirstUnstableOffset()
trace(s"Appended message set with last offset: ${appendInfo.lastOffset}, " +
s"first offset: ${appendInfo.firstOffset}, " +
s"next offset: ${nextOffsetMetadata.messageOffset}, " +
s"and messages: $validRecords")
// 刷盘
if (unflushedMessages >= config.flushInterval)
flush()
appendInfo
}
}
}
下面详细分析一下append中调用的各个方法,首先是analyzeAndValidateRecords,这个方法主要用于检查消息的完整性,并获取这批消息的一些元数据,比如偏移量是否单调递增、有效字节数等:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
private def analyzeAndValidateRecords(records: MemoryRecords, origin: AppendOrigin): LogAppendInfo = {
// 消息批次数
var shallowMessageCount = 0
// 这批消息的有效字节数
var validBytesCount = 0
// 第一条消息的偏移量
var firstOffset: Option[Long] = None
// 最后一条消息的偏移量
var lastOffset = -1L
// 源压缩器
var sourceCodec: CompressionCodec = NoCompressionCodec
// 这批消息的偏移量是否严格单调递增
var monotonic = true
// 这批消息的最大时间戳
var maxTimestamp = RecordBatch.NO_TIMESTAMP
// 最大时间戳的消息的偏移量
var offsetOfMaxTimestamp = -1L
var readFirstMessage = false
// 第一批次中的最后一条消息偏移量
var lastOffsetOfFirstBatch = -1L
// 遍历所有批次
for (batch <- records.batches.asScala) {
// 客户端发来的消息偏移量必须是0,因为偏移量不是由客户端分配的,而是由broker分配的
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2 && origin == AppendOrigin.Client && batch.baseOffset != 0)
throw new InvalidRecordException(s"The baseOffset of the record batch in the append to $topicPartition should " +
s"be 0, but it is ${batch.baseOffset}")
// 读取第一个批次中的第一个偏移量和最后一个偏移量
if (!readFirstMessage) {
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2)
firstOffset = Some(batch.baseOffset)
lastOffsetOfFirstBatch = batch.lastOffset
readFirstMessage = true
}
// 偏移量是否单调递增
if (lastOffset >= batch.lastOffset)
monotonic = false
lastOffset = batch.lastOffset
// 批次大小超过限制,直接抛异常
val batchSize = batch.sizeInBytes
if (batchSize > config.maxMessageSize) {
brokerTopicStats.topicStats(topicPartition.topic).bytesRejectedRate.mark(records.sizeInBytes)
brokerTopicStats.allTopicsStats.bytesRejectedRate.mark(records.sizeInBytes)
throw new RecordTooLargeException(s"The record batch size in the append to $topicPartition is $batchSize bytes " +
s"which exceeds the maximum configured value of ${config.maxMessageSize}.")
}
// 使用CRC校验批次完整性,不完整则直接抛异常
if (!batch.isValid) {
brokerTopicStats.allTopicsStats.invalidMessageCrcRecordsPerSec.mark()
throw new CorruptRecordException(s"Record is corrupt (stored crc = ${batch.checksum()}) in topic partition $topicPartition.")
}
// 记录最大时间戳以及对应偏移量
if (batch.maxTimestamp > maxTimestamp) {
maxTimestamp = batch.maxTimestamp
offsetOfMaxTimestamp = lastOffset
}
// 记录批次数和有效字节数
shallowMessageCount += 1
validBytesCount += batchSize
// 记录压缩器
val messageCodec = CompressionCodec.getCompressionCodec(batch.compressionType.id)
if (messageCodec != NoCompressionCodec)
sourceCodec = messageCodec
}
// 如果broker端配置了别的压缩器,则使用broker端指定的目标压缩器
val targetCodec = BrokerCompressionCodec.getTargetCompressionCodec(config.compressionType, sourceCodec)
// 返回以上所有信息
LogAppendInfo(firstOffset, lastOffset, maxTimestamp, offsetOfMaxTimestamp, RecordBatch.NO_TIMESTAMP, logStartOffset,
RecordConversionStats.EMPTY, sourceCodec, targetCodec, shallowMessageCount, validBytesCount, monotonic, lastOffsetOfFirstBatch)
}
然后是用于进一步检测消息合法性并为消息分配偏移量的validateMessagesAndAssignOffsets方法,这个方法会根据消息压缩情况以及消息格式,调用不同的方法进行合法性校验并分配偏移量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
private[log] def validateMessagesAndAssignOffsets(
// 消息
records: MemoryRecords,
// 分区
topicPartition: TopicPartition,
// 初始偏移量
offsetCounter: LongRef,
time: Time,
now: Long,
// 源和目标压缩器
sourceCodec: CompressionCodec,
targetCodec: CompressionCodec,
// 是否压缩键值
// kafka有两日志清理策略,分别是默认的删除过时消息,另一种是清理key值相同的消息,只保留最新的那条
compactedTopic: Boolean,
// 目标消息格式,一般就是V2
magic: Byte,
// 时间戳类型,分别是默认的由生产者提供(CreateTime),另一种是由broker提供(LogAppendTime)
timestampType: TimestampType,
// 当时间戳类型为CreateTime时,如果消息的时间戳与broker时间的差异超过这个值,broker会拒绝该消息
timestampDiffMaxMs: Long,
// 如果是leader,这是当前的leader epoch,否则是-1
partitionLeaderEpoch: Int,
// 消息来源
origin: AppendOrigin,
// broker通信协议版本
interBrokerProtocolVersion: ApiVersion,
brokerTopicStats: BrokerTopicStats
): ValidationAndOffsetAssignResult = {
if (sourceCodec == NoCompressionCodec && targetCodec == NoCompressionCodec) {
if (!records.hasMatchingMagic(magic))
// 消息格式不同,需要转换成统一格式
convertAndAssignOffsetsNonCompressed(records, topicPartition, offsetCounter, compactedTopic, time, now, timestampType,
timestampDiffMaxMs, magic, partitionLeaderEpoch, origin, brokerTopicStats)
else
// 消息格式相同
assignOffsetsNonCompressed(records, topicPartition, offsetCounter, now, compactedTopic, timestampType, timestampDiffMaxMs,
partitionLeaderEpoch, origin, magic, brokerTopicStats)
} else {
// 需要压缩
validateMessagesAndAssignOffsetsCompressed(records, topicPartition, offsetCounter, time, now, sourceCodec, targetCodec, compactedTopic,
magic, timestampType, timestampDiffMaxMs, partitionLeaderEpoch, origin, interBrokerProtocolVersion, brokerTopicStats)
}
}
可以看到validateMessagesAndAssignOffsets针对这批消息的不同的情况调用了不同方法。当接收的消息格式与目标消息格式不同的时候,将调用convertAndAssignOffsetsNonCompressed方法,这个方法的核心点在于,需要开辟新的空间去容纳转换格式后的消息,并且在转换格式的过程中,顺便分配了偏移量,这一点在builder.appendWithOffset的实现中体现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
// 针对无压缩,并且存在格式不同消息批次的消息校验合法性以及设置偏移量
private def convertAndAssignOffsetsNonCompressed(
records: MemoryRecords,
topicPartition: TopicPartition,
offsetCounter: LongRef,
compactedTopic: Boolean,
time: Time,
now: Long,
timestampType: TimestampType,
timestampDiffMaxMs: Long,
toMagicValue: Byte,
partitionLeaderEpoch: Int,
origin: AppendOrigin,
brokerTopicStats: BrokerTopicStats
): ValidationAndOffsetAssignResult = {
val startNanos = time.nanoseconds
// 根据消息的编码规则,计算这批消息的编码后的存储大小
val sizeInBytesAfterConversion = AbstractRecords.estimateSizeInBytes(toMagicValue, offsetCounter.value,
CompressionType.NONE, records.records)
// 获取该批消息的一些公共信息,如生产者id、sequence
val (producerId, producerEpoch, sequence, isTransactional) = {
val first = records.batches.asScala.head
(first.producerId, first.producerEpoch, first.baseSequence, first.isTransactional)
}
// 分配新的空间去容纳转换格式后的消息
val newBuffer = ByteBuffer.allocate(sizeInBytesAfterConversion)
// 使用builder模式创建格式转换后的消息对象
val builder = MemoryRecords.builder(newBuffer, toMagicValue, CompressionType.NONE, timestampType,
offsetCounter.value, now, producerId, producerEpoch, sequence, isTransactional, partitionLeaderEpoch)
// 获取第一个批次
// 当消息格式是V2或者源压缩器存在的情况下,必须有且仅有一个批次,否则直接抛异常
// 至于为什么要这样,与事务、幂等以及压缩效率相关,在此先不展开讨论
val firstBatch = getFirstBatchAndMaybeValidateNoMoreBatches(records, NoCompressionCodec)
// 校验所有批次消息
for (batch <- records.batches.asScala) {
validateBatch(topicPartition, firstBatch, batch, origin, toMagicValue, brokerTopicStats)
val recordErrors = new ArrayBuffer[ApiRecordError](0)
for ((record, batchIndex) <- batch.asScala.view.zipWithIndex) {
// 校验消息合法性
validateRecord(batch, topicPartition, record, batchIndex, now, timestampType,
timestampDiffMaxMs, compactedTopic, brokerTopicStats).foreach(recordError => recordErrors += recordError)
// 给消息分配偏移量
if (recordErrors.isEmpty)
builder.appendWithOffset(offsetCounter.getAndIncrement(), record)
}
// 处理校验消息合法性出现的错误,即抛异常
processRecordErrors(recordErrors)
}
// 获取转换格式后的消息批对象
val convertedRecords = builder.build()
// 返回转换格式后的消息,以及一些stat数据
val info = builder.info
val recordConversionStats = new RecordConversionStats(builder.uncompressedBytesWritten,
builder.numRecords, time.nanoseconds - startNanos)
ValidationAndOffsetAssignResult(
validatedRecords = convertedRecords,
maxTimestamp = info.maxTimestamp,
shallowOffsetOfMaxTimestamp = info.shallowOffsetOfMaxTimestamp,
messageSizeMaybeChanged = true,
recordConversionStats = recordConversionStats)
}
// MemoryRecordsBuilder.appendWithOffset
private Long appendWithOffset(long offset, boolean isControlRecord, long timestamp, ByteBuffer key,ByteBuffer value, Header[] headers) {
try {
// ...
if (firstTimestamp == null)
firstTimestamp = timestamp;
if (magic > RecordBatch.MAGIC_VALUE_V1) {
appendDefaultRecord(offset, timestamp, key, value, headers);
return null;
} else {
return appendLegacyRecord(offset, timestamp, key, value, magic);
}
} catch (IOException e) {
throw new KafkaException("I/O exception when writing to the append stream, closing", e);
}
}
// MemoryRecordsBuilder.appendDefaultRecord
private void appendDefaultRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value, Header[] headers) throws IOException {
ensureOpenForRecordAppend();
// 每条消息存储的是相对偏移量以及相对时间戳,以节省编码空间
int offsetDelta = (int) (offset - baseOffset);
long timestampDelta = timestamp - firstTimestamp;
// 将消息内容写入输出流
int sizeInBytes = DefaultRecord.writeTo(appendStream, offsetDelta, timestampDelta, key, value, headers);
// stat
recordWritten(offset, timestamp, sizeInBytes);
}
convertAndAssignOffsetsNonCompressed中最后调用builder.build()的时候,其中会调用writeDefaultBatchHeader将这批消息的公共元数据写入缓存作为 header,包括基础偏移量、总大小、生产者ID等。
再来看下assignOffsetsNonCompressed方法,这个方法不需要转换消息格式,因此无需开辟新的空间就可以设置偏移量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
// 针对无压缩,并且格式相同的消息批次校验合法性以及设置偏移量
private def assignOffsetsNonCompressed(
records: MemoryRecords,
topicPartition: TopicPartition,
offsetCounter: LongRef,
now: Long,
compactedTopic: Boolean,
timestampType: TimestampType,
timestampDiffMaxMs: Long,
partitionLeaderEpoch: Int,
origin: AppendOrigin,
magic: Byte,
brokerTopicStats: BrokerTopicStats
): ValidationAndOffsetAssignResult = {
var maxTimestamp = RecordBatch.NO_TIMESTAMP
var offsetOfMaxTimestamp = -1L
val initialOffset = offsetCounter.value
// 获取第一个批次
val firstBatch = getFirstBatchAndMaybeValidateNoMoreBatches(records, NoCompressionCodec)
// 遍历所有批次
for (batch <- records.batches.asScala) {
// 校验批次合法性
validateBatch(topicPartition, firstBatch, batch, origin, magic, brokerTopicStats)
var maxBatchTimestamp = RecordBatch.NO_TIMESTAMP
var offsetOfMaxBatchTimestamp = -1L
val recordErrors = new ArrayBuffer[ApiRecordError](0)
for ((record, batchIndex) <- batch.asScala.view.zipWithIndex) {
// 校验消息合法性
validateRecord(batch, topicPartition, record, batchIndex, now, timestampType,
timestampDiffMaxMs, compactedTopic, brokerTopicStats).foreach(recordError => recordErrors += recordError)
// 记录批次内的最大时间戳及其相应的偏移量
val offset = offsetCounter.getAndIncrement()
if (batch.magic > RecordBatch.MAGIC_VALUE_V0 && record.timestamp > maxBatchTimestamp) {
maxBatchTimestamp = record.timestamp
offsetOfMaxBatchTimestamp = offset
}
}
// 处理校验消息合法性出现的错误,即抛异常
processRecordErrors(recordErrors)
// 记录最大时间戳及其相应偏移量
if (batch.magic > RecordBatch.MAGIC_VALUE_V0 && maxBatchTimestamp > maxTimestamp) {
maxTimestamp = maxBatchTimestamp
offsetOfMaxTimestamp = offsetOfMaxBatchTimestamp
}
// 设置批次内的最大偏移量
batch.setLastOffset(offsetCounter.value - 1)
// 设置批次的leader epoch
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2)
batch.setPartitionLeaderEpoch(partitionLeaderEpoch)
// 设置批次的最大时间戳
if (batch.magic > RecordBatch.MAGIC_VALUE_V0) {
if (timestampType == TimestampType.LOG_APPEND_TIME)
batch.setMaxTimestamp(TimestampType.LOG_APPEND_TIME, now)
else
batch.setMaxTimestamp(timestampType, maxBatchTimestamp)
}
}
// 如果时间戳类型是LogAppendTime,则这批消息的最大时间戳应该是当前broker时间
if (timestampType == TimestampType.LOG_APPEND_TIME) {
maxTimestamp = now
if (magic >= RecordBatch.MAGIC_VALUE_V2)
offsetOfMaxTimestamp = offsetCounter.value - 1
else
offsetOfMaxTimestamp = initialOffset
}
// 返回结果
ValidationAndOffsetAssignResult(
validatedRecords = records,
maxTimestamp = maxTimestamp,
shallowOffsetOfMaxTimestamp = offsetOfMaxTimestamp,
messageSizeMaybeChanged = false,
recordConversionStats = RecordConversionStats.EMPTY)
}
这里有一个值得注意的地方,我们将这个assignOffsetsNonCompressed方法和之前的convertAndAssignOffsetsNonCompressed比较发现,assignOffsetsNonCompressed并没有为每个消息写入其偏移量,最终每条消息却能得到正确的偏移量,通过调试发现,运行了 batch.setLastOffset(offsetCounter.value - 1) 之后,batch 里的每个消息的偏移量从 0 值变成了正确的偏移量。
举个例子,当前 LEO=10,此时 append 了 4 条消息进来,并且这四条消息都在同一个 batch,此时 batch 的偏移量范围显示为 [0, 3],并且对每条消息调用 offset() 返回 0。运行了 batch.setLastOffset 之后,此时 batch 的偏移量范围显示为 [10, 13],并且每条消息偏移量依次为 10, 11, 12, 13。
点进这个方法的实现看一下:
1
2
3
4
5
6
7
8
@Override
public void setLastOffset(long offset) {
buffer.putLong(BASE_OFFSET_OFFSET, offset - lastOffsetDelta());
}
private int lastOffsetDelta() {
return buffer.getInt(LAST_OFFSET_DELTA_OFFSET);
}
我们知道批次的数据是存储在 buffer 上的,这里通过设置 lastOffset,再加上 batch 已知的 offsetDelta,即批次内最大和最小偏移量差值,就能计算出每条整个批次的偏移量范围,以及每条消息的偏移量。当然,消息批次 RecordBatch 作为 kafka 消息处理的主要基本单位,还有其他一些类似 setLastOffset 的方法,只需要 O(1) 复杂度就能作用到批次内的所有消息。
另外validateMessagesAndAssignOffsetsCompressed方法其实就大同小异了,不过是多了个消息压缩,不再费篇幅介绍。
综上,对append方法总结如下:该方法目的就是将客户端发来的一批消息存储到 broker 中,主要进行了以下几步核心操作:
- 检查消息合法性
- 为消息转换格式、压缩以及分配偏移量(partition leader)或者检查偏移量合法性(partition follower)
- 如果有必要的话,切分日志段
- 将消息写入日志段
- 更新 LEO、事务、刷盘等
读取消息
既然有新增/写入(append),那必然就有读取(read)。这个read方法返回类型与日志段的read方法返回类型相同,都是FetchDataInfo。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
def read(
// 读取的起始偏移量
startOffset: Long,
// 读取最大字节数
maxLength: Int,
// 隔离级别,主要控制能读取的最大偏移量,一般用于事务
isolation: FetchIsolation,
// 是否至少返回一条消息,即使这条消息大小超过maxLength
minOneMessage: Boolean
): FetchDataInfo = {
maybeHandleIOException(s"Exception while reading from $topicPartition in dir ${dir.getParent}") {
val includeAbortedTxns = isolation == FetchTxnCommitted
val endOffsetMetadata = nextOffsetMetadata
val endOffset = endOffsetMetadata.messageOffset
// 获取baseOffset <= startOffset的baseOffset最大的日志段
var segmentEntry = segments.floorEntry(startOffset)
// startOffset超出可读范围,直接抛异常
if (startOffset > endOffset || segmentEntry == null || startOffset < logStartOffset)
throw new OffsetOutOfRangeException(s"Received request for offset $startOffset for partition $topicPartition, " +
s"but we only have log segments in the range $logStartOffset to $endOffset.")
// 根据隔离级别确定读取消息偏移量的上限
val maxOffsetMetadata = isolation match {
case FetchLogEnd => endOffsetMetadata
case FetchHighWatermark => fetchHighWatermarkMetadata
case FetchTxnCommitted => fetchLastStableOffsetMetadata
}
// startOffset超过上限,返回空
if (startOffset == maxOffsetMetadata.messageOffset) {
return emptyFetchDataInfo(maxOffsetMetadata, includeAbortedTxns)
} else if (startOffset > maxOffsetMetadata.messageOffset) {
val startOffsetMetadata = convertToOffsetMetadataOrThrow(startOffset)
return emptyFetchDataInfo(startOffsetMetadata, includeAbortedTxns)
}
// 从日志段读取消息数据
while (segmentEntry != null) {
val segment = segmentEntry.getValue
// 确定读取日志段的物理位置上限
val maxPosition = {
if (maxOffsetMetadata.segmentBaseOffset == segment.baseOffset) {
maxOffsetMetadata.relativePositionInSegment
} else {
segment.size
}
}
// 读取
val fetchInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage)
if (fetchInfo == null) {
// startOffset已经超出了该日志段的最大偏移量,获取下一个日志段
// 这种情况是可能发生的,因为事务(或其他原因)可能导致偏移量不是连续的,因此startOffset可能大于当前日志段的lastOffset并且小于下一个日志段的baseOffset
segmentEntry = segments.higherEntry(segmentEntry.getKey)
} else {
return if (includeAbortedTxns)
// 事务相关,忽略...
addAbortedTransactions(startOffset, segmentEntry, fetchInfo)
else
fetchInfo
}
}
// 边界情况,startOffset比最后一个日志段的偏移量的lastOffset还要大
FetchDataInfo(nextOffsetMetadata, MemoryRecords.EMPTY)
}
}
综上,读消息方法还是比新增消息方法简单许多,只需要稍微注意到偏移量不连续的问题,可能需要遍历下一个日志段。
总结
本篇首先过了一下前两篇多次在代码中出现过的 leader epoch 的概念,以及简单说明了其解决了什么问题。其次,分析了日志对日志段的管理(增删改查、切分)。最后用大篇幅重点分析了日志如何新增消息以及读取消息。