kafka源码阅读(2)-日志及其初始化
基于开源 kafka 2.5 版本。
如无特殊说明,文中代码片段将删除 debug 信息、异常触发、英文注释等代码,以便观看核心代码。
本篇将基于上一篇介绍的日志段,进一步探索 kafka 中的日志,包括如何加载管理日志段等操作。如无特别修饰,文中所述的“文件夹”均代指本 Log 中文件夹。
日志 Log
首先大致浏览一下Log类的一些重要成员,有个印象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class Log(
// 该日志的文件夹
@volatile var dir: File,
@volatile var config: LogConfig,
// 日志的当前起始偏移量,随着日志的清理和截断而更新,偏移量在 logStartOffset 之前的消息对用户不可见
@volatile var logStartOffset: Long,
@volatile var recoveryPoint: Long,
scheduler: Scheduler,
brokerTopicStats: BrokerTopicStats,
val time: Time,
val maxProducerIdExpirationMs: Int,
val producerIdExpirationCheckIntervalMs: Int,
val topicPartition: TopicPartition,
val producerStateManager: ProducerStateManager,
logDirFailureChannel: LogDirFailureChannel
) {
// 插入日志的下一条消息偏移量,即LEO
@volatile private var nextOffsetMetadata: LogOffsetMetadata = _
// 高水位,即HW,表示已提交与未提交消息的分隔点
@volatile private var highWatermarkMetadata: LogOffsetMetadata = LogOffsetMetadata(logStartOffset)
// 该日志所包含的所有日志段
private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
}
目前我们只需要了解以上有注释的这些成员。对于 logStartOffset 这个成员,结合 LEO、high watermark 这些重要偏移量,用一张图描述一下:
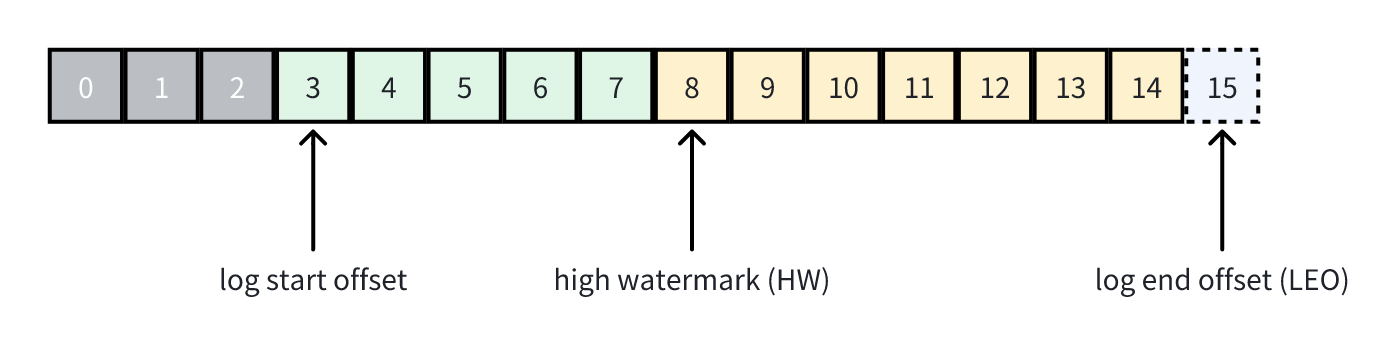
如图所示,从 log start offset 开始的消息都对用户可见(可访问),从 HW 开始的消息都未提交(uncommited),LEO 为下一条待插入消息的偏移量。其中,HW 是对于整个分区副本集而言的,它的值是所有 ISR(in-sync replicas)副本分区中的最小 LEO,该值用于确保哪些消息是已经被正确提交的。另外,你可能还听说过 LSO 这个偏移量,但它并不是 log start offset,而是 kafka 事务中存在的概念 log stable offset,暂时不需要理会。
Log 的初始化
首先 Log 类中有一个 locally 代码块,关于 locally 本身的作用在此不多讲,这块代码将会在构造 Log 类的时候被执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
locally {
// 创建日志文件夹
Files.createDirectories(dir.toPath)
// 分区副本相关,后续会讲
initializeLeaderEpochCache()
// 加载日志段
val nextOffset = loadSegments()
nextOffsetMetadata = LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)
// 分区副本相关,后续会讲
leaderEpochCache.foreach(_.truncateFromEnd(nextOffsetMetadata.messageOffset))
updateLogStartOffset(math.max(logStartOffset, segments.firstEntry.getValue.baseOffset))
leaderEpochCache.foreach(_.truncateFromStart(logStartOffset))
// 事务相关,忽略
if (!producerStateManager.isEmpty)
throw new IllegalStateException("Producer state must be empty during log initialization")
loadProducerState(logEndOffset, reloadFromCleanShutdown = hasCleanShutdownFile)
}
可以看到 Log 初始化还是干了不少事情,但重点是看到加载日志段这里,loadSegments这个方法负责加载日志段,核心功能就是构造相应的 LogSegmemt 对象。
更具体地来说,loadSegments会清理一些无用文件,随后执行宕机前没执行完毕的 swap 操作,将 .swap 文件恢复为正常的 .log 日志文件,并在内存中构造出相应的 LogSegment 对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
private def loadSegments(): Long = {
// 删除无用的文件(包括.deleted, .cleaned, 以及无效的.swap文件),返回需要被恢复的 .swap 文件
val swapFiles = removeTempFilesAndCollectSwapFiles()
// 加载所有的日志和索引文件
retryOnOffsetOverflow {
logSegments.foreach(_.close())
segments.clear()
loadSegmentFiles()
}
// 执行swap操作,即将旧日志段转换成新日志段
completeSwapOperations(swapFiles)
if (!dir.getAbsolutePath.endsWith(Log.DeleteDirSuffix)) {
// 恢复日志段,确保所有未刷盘的数据都被正确恢复,截断损坏的数据
val nextOffset = retryOnOffsetOverflow {
recoverLog()
}
// reset the index size of the currently active log segment to allow more entries
activeSegment.resizeIndexes(config.maxIndexSize)
nextOffset
} else {
if (logSegments.isEmpty) {
addSegment(LogSegment.open(dir = dir,
baseOffset = 0,
config,
time = time,
fileAlreadyExists = false,
initFileSize = this.initFileSize,
preallocate = false))
}
0
}
}
loadSegments方法首先调用removeTempFilesAndCollectSwapFiles遍历并删除了文件夹中的一些无效文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
private def removeTempFilesAndCollectSwapFiles(): Set[File] = {
// 该函数会删除指定的索引文件
def deleteIndicesIfExist(baseFile: File, suffix: String = ""): Unit = {
val offset = offsetFromFile(baseFile)
Files.deleteIfExists(Log.offsetIndexFile(dir, offset, suffix).toPath)
Files.deleteIfExists(Log.timeIndexFile(dir, offset, suffix).toPath)
Files.deleteIfExists(Log.transactionIndexFile(dir, offset, suffix).toPath)
}
var swapFiles = Set[File]()
var cleanFiles = Set[File]()
// .cleaned文件最小偏移量
var minCleanedFileOffset = Long.MaxValue
// 遍历文件夹中的文件
for (file <- dir.listFiles if file.isFile) {
val filename = file.getName
if (filename.endsWith(DeletedFileSuffix)) {
// .deleted文件,直接删除
Files.deleteIfExists(file.toPath)
} else if (filename.endsWith(CleanedFileSuffix)) {
// .cleaned文件,记录最小偏移量以及文件
minCleanedFileOffset = Math.min(offsetFromFileName(filename), minCleanedFileOffset)
cleanFiles += file
} else if (filename.endsWith(SwapFileSuffix)) {
// .swap文件,可能是索引文件或者是日志文件,无论如何都会删除相应的索引文件,如果是日志文件则稍后会重建索引
val baseFile = new File(CoreUtils.replaceSuffix(file.getPath, SwapFileSuffix, ""))
if (isIndexFile(baseFile)) {
deleteIndicesIfExist(baseFile)
} else if (isLogFile(baseFile)) {
deleteIndicesIfExist(baseFile)
swapFiles += file
}
}
}
// 从待恢复的.swap文件中找到偏移量比minCleanedFileOffset大的.swap文件,这些文件可能不完整,直接删除它们的索引以及日志文件
val (invalidSwapFiles, validSwapFiles) = swapFiles.partition(file => offsetFromFile(file) >= minCleanedFileOffset)
invalidSwapFiles.foreach { file =>
val baseFile = new File(CoreUtils.replaceSuffix(file.getPath, SwapFileSuffix, ""))
deleteIndicesIfExist(baseFile, SwapFileSuffix)
Files.deleteIfExists(file.toPath)
}
// 删除.cleaned文件
cleanFiles.foreach { file =>
debug(s"Deleting stray .clean file ${file.getAbsolutePath}")
Files.deleteIfExists(file.toPath)
}
// 返回所有有效的.swap文件
validSwapFiles
}
在上一篇介绍了我们核心的文件比如 .log, .index 等,这里又涉及到几个新的后缀名文件,这里有必要说明一些这些不同后缀名分别代表了什么。
- .deleted:kafka 在删除日志段的时候是异步删除,具体是将 .log 文件后缀先改成 .deleted文件,然后再异步删除
- .cleaned:这个文件包含了 kafka 执行日志压缩后的结果,如果压缩过程宕机,那么这些不完整的 .cleaned 文件会被删除
- .swap:当多个日志段压缩成一个日志段或者一个日志段因为偏移量溢出而拆分成多个日志段时,会产生 .swap 文件
之后的源码分析还会遇到这些文件的具体作用并进行解释。总的来说 kafka 弄出这些后缀的文件,可以简单理解为 kafka 是为了保证文件操作的原子性、避免宕机丢失数据错误以及其它可能的错误。
logSegments接着调用了loadSegmentFiles来加载文件夹中现有的日志,比较简单不多说,需要注意的是LogSegment.recover被调用对日志段进行恢复的时候,如果检测到日志段的消息偏移量溢出,会将一个大段文件分割成多个小段文件,并再次调用loadSegmentFiles重新开始加载日志段。
loadSegments接着调用completeSwapOperations,这个方法用于将之前得到的有效 .swap 文件转换成日志段,以替换旧的日志段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
private def completeSwapOperations(swapFiles: Set[File]): Unit = {
// 遍历每个.swap文件
for (swapFile <- swapFiles) {
val logFile = new File(CoreUtils.replaceSuffix(swapFile.getPath, SwapFileSuffix, ""))
val baseOffset = offsetFromFile(logFile)
// 构造并恢复日志段
val swapSegment = LogSegment.open(swapFile.getParentFile,
baseOffset = baseOffset,
config,
time = time,
fileSuffix = SwapFileSuffix)
recoverSegment(swapSegment)
// 注意这里的逻辑,何为oldSegment?首先.swap文件可能因为以下两种原因产生
// 1. 日志段被分割成多个日志段,swapSegment是oldSegment的子集
// 2. 多个日志段被合并成一个日志段,oldSegment是swapSegment的子集
// 因此这里的oldSegment与swapSegment其实是对应起来的
val oldSegments = logSegments(swapSegment.baseOffset, swapSegment.readNextOffset).filter { segment =>
segment.readNextOffset > swapSegment.baseOffset
}
// 删除旧的日志段,并将.swap文件后缀重命名为.log作为新的日志段
replaceSegments(Seq(swapSegment), oldSegments.toSeq, isRecoveredSwapFile = true)
}
}
loadSegments接着调用recoverLog来执行恢复日志操作,该函数主要是调用了recoverSegment方法来对所有日志段进行恢复。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
private def recoverLog(): Long = {
// 如果之前程序是优雅退出的(存在以.kafka_cleanshutdown结尾的文件),则不需要执行恢复操作
if (!hasCleanShutdownFile) {
// 获取恢复点之外的所有日志段对象
val unflushed = logSegments(this.recoveryPoint, Long.MaxValue).toIterator
var truncated = false
// 遍历需要恢复的日志段
while (unflushed.hasNext && !truncated) {
val segment = unflushed.next
val truncatedBytes =
try {
// 恢复日志段
recoverSegment(segment, leaderEpochCache)
} catch {
case _: InvalidOffsetException =>
val startOffset = segment.baseOffset
segment.truncateTo(startOffset)
}
if (truncatedBytes > 0) {
// 将该日志段截断到最后合法的位置
removeAndDeleteSegments(unflushed.toList, asyncDelete = true)
truncated = true
}
}
}
if (logSegments.nonEmpty) {
val logEndOffset = activeSegment.readNextOffset
if (logEndOffset < logStartOffset) {
// 发现LEO比logStartOffset小,直接删除所有日志段
removeAndDeleteSegments(logSegments, asyncDelete = true)
}
}
if (logSegments.isEmpty) {
// 如果日志为空,创建一个空的日志段
addSegment(LogSegment.open(dir = dir,
baseOffset = logStartOffset,
config,
time = time,
fileAlreadyExists = false,
initFileSize = this.initFileSize,
preallocate = config.preallocate))
}
// 更新恢复点为LEO
recoveryPoint = activeSegment.readNextOffset
recoveryPoint
}
另外我们注意到之前的loadSegmentFiles和completeSwapOperations中也有调用recoverSegment方法,那为什么recoverLog又要统一再调用一次?
loadSegmentFiles:调用recoverSegment目的是重建索引completeSwapOperations:调用recoverSegment的目的是保证 .swap 文件对应的日志段能够正确地转换成日志段,确保 swap 的正确执行recoverLog:调用recoverSegment确保所有日志段的完整性
个人认为,就这么看的话对同一个日志段可能会被重复调用 recoverSegment,这部分源码感觉可以优化一下。
总结
本篇介绍了 Log 初始化都干了些什么,核心是加载日志段到内存中,并且清理了一些不再需要的文件,让文件夹中变得干净,以便后续进行对日志段的管理。
参考
极客时间《Kafka核心源码解读》——胡夕
KIP-101 - Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation