kafka源码阅读(1)-日志段的读/写/恢复
基于开源 kafka 2.5 版本 。
如无特殊说明,文中代码片段将删除 debug 信息、异常的代码 path 等代码,以便观看核心代码。
本篇将探索 kafka 中的日志段(LogSegment)。这里的日志(Log)指的是kafka存储的消息,而不是平时打印到命令行的那种日志。
日志的基本结构
首先要基本了解kafka的基本结构,一个日志(Log)代表一个 kafka 分区(Partition)的数据存储实现,结合下图进行理解,每个日志包含多个分段(Segment),每个分段由磁盘上的一组文件来表示,包括数据文件(.log)、偏移量索引文件(.index)、时间戳索引文件(.timeindex),如果使用了kafka事务还会包含事务相关索引文件(.txnindex)。
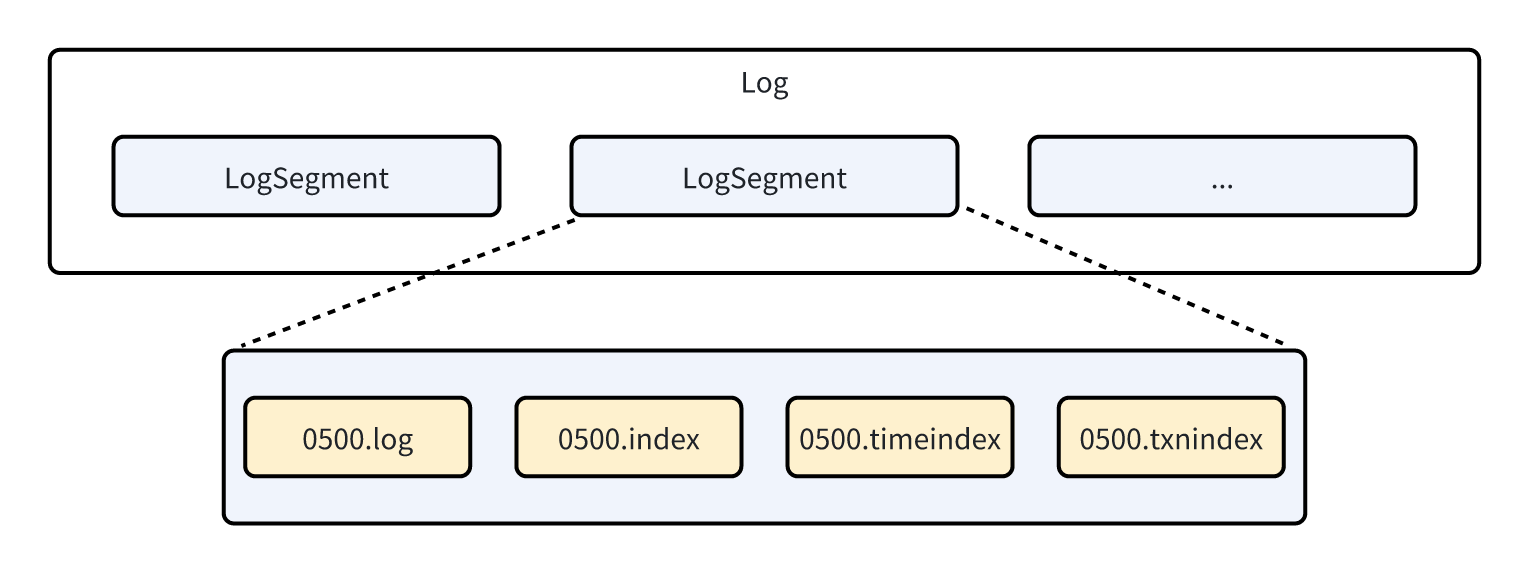
索引文件非常重要,当我们查找某个偏移量的消息时,势必要遍历 .log 文件中的所有数据,而偏移量索引文件通过类似跳表那样的稀疏索引机制,来做到一次查找可以跳过许多不必要的读数据操作,但又没有跳表那么复杂,可以简单看成是只有两层的跳表,上层是 .index,下层是 .log,其索引方式大致如图所示:

日志的核心代码保存在core模块下的kafka.log包下。
日志段 LogSegment
日志段代码位于 LogSegment.scala 文件中,我们重点关注里面的LogSegment类,及其三个核心公有方法:append, read, recover。首先看一下LogSegment的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class LogSegment private[log] (
// 消息日志
val log: FileRecords,
// 索引
val lazyOffsetIndex: LazyIndex[OffsetIndex],
// 时间戳索引
val lazyTimeIndex: LazyIndex[TimeIndex],
// 事务索引
val txnIndex: TransactionIndex,
// 起始offset
val baseOffset: Long,
// 索引最大间隔
val indexIntervalBytes: Int,
// 创建日志段倒计时扰动
val rollJitterMs: Long,
val time: Time
) extends Logging { … }
首先前四个属性基本对应代表日志段的上述四个文件,不再多说,起始offset也很好理解,代表该分段中第一条消息的起始偏移量。我们知道 .index 文件是用来索引 .log 文件里的消息的,每个索引之间的间隔应该多大则由索引最大间隔来决定,比如 indexIntervalBytes=256B,那么 .index 文件相邻两个索引映射到 .log 文件上之间的距离至少是 256B。rollJitterMs后面会说,基本不影响分析。time用于统计数据,不影响核心流程。
日志段的核心方法
append
append用于将一批消息数据写入日志段中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def append(
// 这批消息中的最大偏移量
largestOffset: Long,
// 这批消息中的最大时间戳
largestTimestamp: Long,
// 这批消息中的最大时间戳消息的偏移量
shallowOffsetOfMaxTimestamp: Long,
// 这批消息
records: MemoryRecords
): Unit = {
if (records.sizeInBytes > 0) {
val physicalPosition = log.sizeInBytes()
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
// 规定日志段的最大相对偏移量不能超出int范围
ensureOffsetInRange(largestOffset)
// 写入这批消息
val appendedBytes = log.append(records)
// Update the in memory max timestamp and corresponding offset.
if (largestTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = largestTimestamp
offsetOfMaxTimestampSoFar = shallowOffsetOfMaxTimestamp
}
// 新增一条索引
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0
}
// 等下一次写入消息时,发现上一次超出了索引最大间隔的时候再去新增索引,避免新增不必要的索引
bytesSinceLastIndexEntry += records.sizeInBytes
}
}
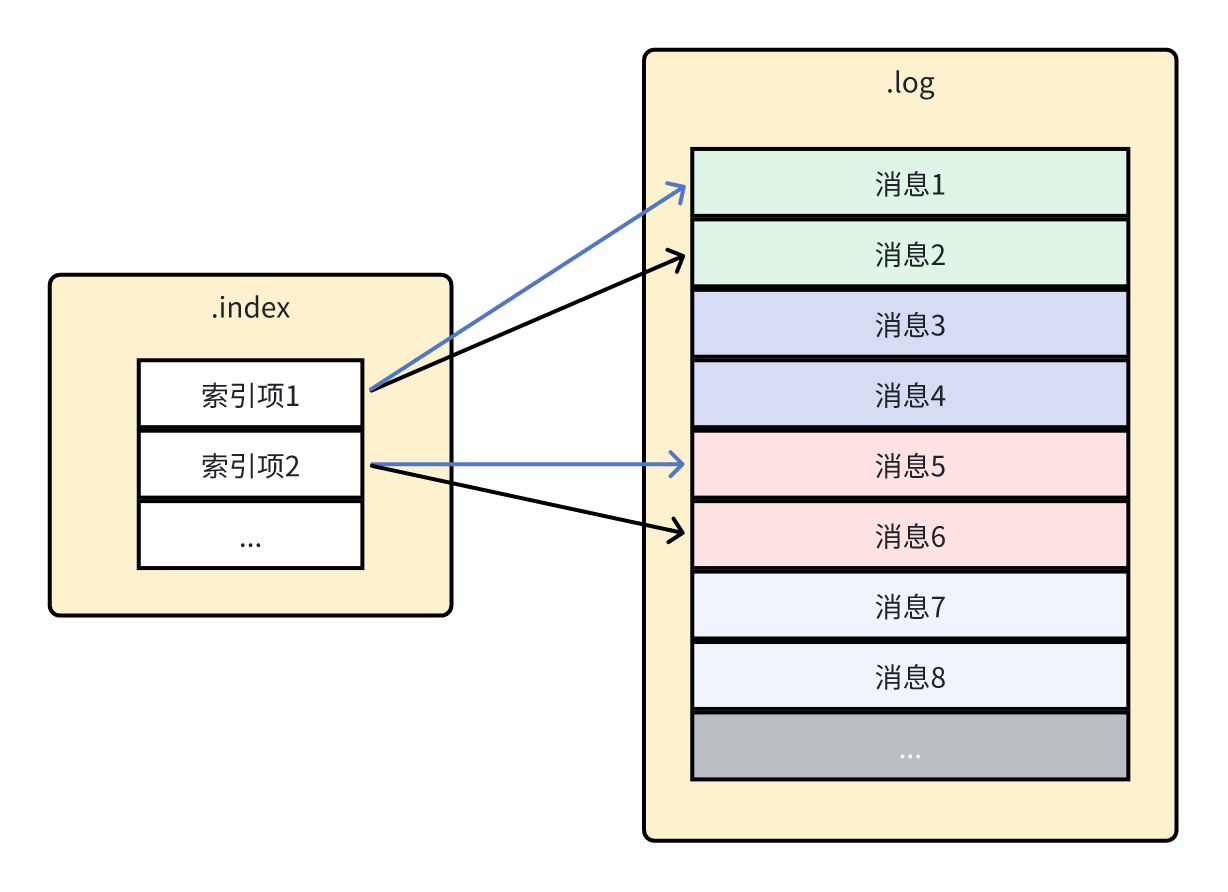
代码注释已经说明了写入消息的流程,我暂时忽略了对时间戳相关说明,只聚焦于核心的 .log 和 .index 相关代码。另外还需注意到新增索引的时候,映射关系为:批次最后一条消息的偏移量 -> 批次第一条消息的物理位置。因此更精确地表示索引大致如下图所示,其中 .log 文件中不同颜色的消息为不同的批次,.index 文件的黑色箭头为索引键,蓝色箭头为索引值。
read
read方法用于从日志段中读取一批消息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def read(
// 这批消息的最小偏移量>=startOffset
startOffset: Long,
// 这批消息的最大字节数<=maxSize
maxSize: Int,
// 这批消息的最大物理位置
maxPosition: Long = size,
// 如果消息大小超出最大可读字节数,是否至少返回一条消息
minOneMessage: Boolean = false
): FetchDataInfo = {
// 找到偏移量大于startOffset的第一批消息
val startOffsetAndSize = translateOffset(startOffset)
// if the start position is already off the end of the log, return null
if (startOffsetAndSize == null)
return null
// 从这批消息中第一条消息的物理位置开始读取
val startPosition = startOffsetAndSize.position
val offsetMetadata = LogOffsetMetadata(startOffset, this.baseOffset, startPosition)
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
else maxSize
// return a log segment but with zero size in the case below
if (adjustedMaxSize == 0)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
// 确定这批消息的最终大小上限
val fetchSize: Int = min((maxPosition - startPosition).toInt, adjustedMaxSize)
// 使用log.slice读取一批消息
FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize),
firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)
}
跟着上述注释,可以发现read方法的流程也是非常直观的。这里值得注意的是,translateOffset这个方法虽然说返回 >= startOffset的第一条消息,但 kafka 是以 RecordBatch 为单位进行读写、压缩等操作的,因此返回的其实是一批消息,里面的消息可能前半部分的偏移量 < startOffset,而后半部分才 >= startOffset,kafka 服务端会全部读取并返回给客户端,另外注意到read返回的信息中,偏移量是startOffset,kafka 的客户端代码将会通过该偏移量来过滤掉那些偏移量 < startOffset的消息,再把后面剩下的偏移量 >= startOffset的消息返回给上层业务去使用。这样设计的好处是 kafka 服务端与客户端之间只需无脑以 RecordBatch 为单位进行数据传输,加上传输一点必要的过滤条件/元数据(比如startOffset),由 kafka 客户端库负责过滤掉无用消息。
recover
recover方法用于 broker 启动或崩溃恢复时重建日志段的索引文件并确保日志文件的完整性。这个函数会读取硬盘上所有的日志,然后以批的粒度重建索引,以及处理元数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
def recover(producerStateManager: ProducerStateManager, leaderEpochCache: Option[LeaderEpochFileCache] = None): Int = {
// 清空所有索引文件,为重建索引做准备
offsetIndex.reset()
timeIndex.reset()
txnIndex.reset()
var validBytes = 0
var lastIndexEntry = 0
maxTimestampSoFar = RecordBatch.NO_TIMESTAMP
try {
for (batch <- log.batches.asScala) {
// 如果批次不合法会抛出异常
batch.ensureValid()
ensureOffsetInRange(batch.lastOffset)
// 重建最大时间戳及其对应的偏移量
if (batch.maxTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = batch.maxTimestamp
offsetOfMaxTimestampSoFar = batch.lastOffset
}
// 重建索引
if (validBytes - lastIndexEntry > indexIntervalBytes) {
offsetIndex.append(batch.lastOffset, validBytes)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
lastIndexEntry = validBytes
}
validBytes += batch.sizeInBytes()
if (batch.magic >= RecordBatch.MAGIC_VALUE_V2) {
// 发现更大的leader epoch,更新leader epoch
leaderEpochCache.foreach { cache =>
if (batch.partitionLeaderEpoch > 0 && cache.latestEpoch.forall(batch.partitionLeaderEpoch > _))
cache.assign(batch.partitionLeaderEpoch, batch.baseOffset)
}
// 事务相关,忽略...
updateProducerState(producerStateManager, batch)
}
}
} cache(...) { ... }
// 将该日志段截断到最后合法的位置
val truncated = log.sizeInBytes - validBytes
log.truncateTo(validBytes)
offsetIndex.trimToValidSize()
// A normally closed segment always appends the biggest timestamp ever seen into log segment, we do this as well.
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar, skipFullCheck = true)
timeIndex.trimToValidSize()
truncated
}
注意到log.sizeInBytes可能会出现大于validBytes(前面合法批次的总大小)的情况,换句话说,可能日志段中会出现非法批次,这种情况的一些常见原因有比如写入消息时机器宕机导致批次写入不完整,或者是事务完成之前服务器崩溃,这些数据虽然完整但同样被视为无效数据。一旦遍历到非法批次,该批次包括后面的批次全部都需要被截断。这种截断机制保证了 kafka 在崩溃恢后能恢复到一致的状态,但可能会丢失一些最近写入的消息,这就是为什么在要求严格持久性的场景中,生产者通常会使用 acks=all 和 min.insync.replicas 设置,以确保数据在被确认前已经安全地复制到多个副本。
最后,RecordBatch.magic表示记录批次的消息格式版本,分别有以下三个版本:
- MAGIC_VALUE_V0:最早的消息格式,Kafka 0.8.0版本引入
- MAGIC_VALUE_V1:在Kafka 0.10.0版本引入,添加了消息时间戳
- MAGIC_VALUE_V2:在Kafka 0.11.0版本引入,支持事务和幂等性
现在一般使用的都是 V2,因此之后的源码分析都默认使用的是 V2 版本的消息格式。
总结
本篇首先介绍了 kafka 日志与日志段的关系,一个分区对应一个日志,在硬盘上表现为一个文件夹。日志又由多个日志段组成,每个日志段包含实际存储消息的 .log 文件以及多个索引文件(如 .index、.timeindex、.txnindex)。
接着深入分析了日志段类LogSegment的三个核心方法,分别是负责将消息追加到日志并维护索引的append、根据偏移量读取消息的read以及用于系统异常或重启后的日志段恢复的recover方法。
综合而言,LogSegment 的各个核心方法不难理解,简单来说就是管好那几个日志和索引文件即可。
参考
极客时间《Kafka核心源码解读》——胡夕