golang sync包源码阅读
前言
sync包提供了常见的并发编程工具,比如最常见的Mutex、WaitGroup等。这些工具都非常简洁,几乎0学习成本。本篇将从源码角度简单看看这些工具的实现原理,以在未来有需求的时候,理解甚至是手动实现功能更强大的,更复杂的并发编程工具。
sync.Mutex
sync.Mutex是golang中的互斥锁,但是注意它仅仅具有互斥访问的功能,没有其他功能,比如不支持可重入、不可自定义公平/非公平。
公平性
对于公平性,Mutex采取了综合两者的做法:
- normal mode(非公平模式,利于高效率运行):锁释放时,优先让同时新来尝试获取锁的线程获取到锁,而不是等待队列中的线程,运行成本低,只需数次CAS就能获取到锁。这是默认的模式
- starvation mode(公平模式,避免高并发下线程饿死):锁释放时,优先让等待队列的线程获取到锁,而不是新来的线程。当等待队列队头线程等待超过1ms进入公平模式
如果当前为公平模式,那么当等待队列唯一的队头线程获取到锁,或者队头线程等待时间不足1ms,又会自动回到非公平模式。
可重入性
在开始源码之前,关于为什么golang的官方互斥锁不考虑支持可重入性我想简单讨论下。Russ Cox在讨论里核心观点在于:互斥锁的目的是保护程序的不变性(即invariant,关于什么是程序的不变性可以参考这篇)。因此当线程获取到互斥锁以及释放锁的那一刻,程序都应该是invariant的,在持有锁的期间,程序可以随便破坏invariant,只要保证释放锁的那一刻恢复了invariant即可。从这个观点来说,如果锁是可重入的,就会有这样的情况发生:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
func G() {
mu.Lock()
// 破坏invariant
...
F()
// 恢复invariant
...
mu.Unlock()
}
func F() {
mu.Lock()
// 此时持有锁,程序应该是invariant的
// 继续执行下去可能会导致bug,因为F认为持有锁的那一刻程序是invariant的
// 但F不知道invariant已经被G破坏
...
mu.Unlock()
}
也就是说,Russ Cox给互斥锁功能上的定义是保持程序的invariant,因此可重入锁的想法就是错的。但也有别的观点认为他对互斥锁的定义是错的,互斥锁本身就是为了避免多线程访问修改变量,invariant是开发者的责任,与你用不用互斥锁无关,互斥锁只是帮助你实现invariant的,并且出于编程上的方便,可重入锁可以make your life easier!况且很多语言其实都支持可重入锁。
另外关于invariant,本人也不认为是互斥锁的责任,比如在单线程的程序中,你需要维护(a==b)==true这个invariant,而且由于单线程你根本不需要锁,那么只要你会改变a或者改变b,就肯定会有某些时刻会出现invariant被破坏的情况,但这些情况一般是函数内部的瞬时发生的,而函数执行前后都是保持invariant的就没问题,可以看到与锁无关。因此锁只是个实现invariant的工具之一,它只需要关注底层并发的事情,不需要给他下“保持程序的invariant”这样的高层抽象定义。
后面我们会利用sync包现有的工具,尝试实现一个可重入锁。
源码
Mutex结构体:
1
2
3
4
5
6
7
8
9
10
const (
mutexLocked = 1 << iota // 锁是否被线程持有
mutexWoken // 是否有被唤醒的线程正在等待获取锁
mutexStarving // 是否处于饥饿模式
)
type Mutex struct {
state int32 // 低三位分别对应上述三个状态,高位记录等待队列的线程数
sema uint32 // 给底层同步原语使用的信号量
}
Lock方法:
1
2
3
4
5
6
7
8
9
10
11
func (m *Mutex) Lock() {
// Fast path: 使用CAS快速加锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path: CAS加锁失败,说明锁被其他线程占有,当前应该被阻塞
m.lockSlow()
}
lockSlow方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false // 线程饥不饥饿
awoke := false // 线程是不是唤醒状态
iter := 0 // 自旋次数
old := m.state
for {
// 如果不饥饿,表明是非公平模式,尝试自旋等待锁释放
// 自选若干次,等到达到最大自旋次数或者锁释放就停止自旋
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// 如果当前没有其它醒着的线程,当前线程视为醒着,让Unlock的线程不要唤醒阻塞的线程
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
new := old
// 如果不饥饿,表明是非公平模式,当前线程可以去竞争锁
if old&mutexStarving == 0 {
new |= mutexLocked
}
// 如果有锁或者饥饿,表明当前线程将会阻塞等待锁释放,waiter+1
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// 如果需要饥饿,并且有锁,那么设为饥饿
// 为什么锁已经释放的情况下不能设为饥饿,首先waiter只会由Unlock来唤醒,如果锁已经被释放了,而这里又设成饥饿变成公平锁,新来的线程直接进入等待队列被阻塞,并且原来的waiter因为阻塞也不可能获取到锁,最终导致没有线程来Unlock
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
// 这个线程可能即将会通过CAS直接获取到锁或者进入阻塞,将唤醒状态设回0
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
// 尝试CAS将state设成new
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 通过CAS成功获取到锁,返回
if old&(mutexLocked|mutexStarving) == 0 {
break
}
// 运行到这里说明之前是有锁或者饥饿的状态,应该阻塞当前线程
// 阻塞并等待被唤醒。新来的线程放到队尾,被唤醒的线程放到队头
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 被唤醒后,检查是否应该进入饥饿模式
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
// 如果是饥饿的,那么应该直接把锁交给这个被唤醒的线程
if old&mutexStarving != 0 {
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 设置为加锁,并且waiter-1
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
// 如果当前线程没有饥饿,或者这个是最后一个waiter,那么退出饥饿模式
delta -= mutexStarving
}
// 通过阻塞唤醒后获取到锁,返回
atomic.AddInt32(&m.state, delta)
break
}
// 以唤醒的状态重新走一遍流程
awoke = true
iter = 0
} else {
// CAS失败,重来一遍上述流程
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
Unlock方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// 因为当前线程持有锁,所有直接state-mutexLocked就行
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// new!=0说明可能有其他线程在等待,还要进一步处理
m.unlockSlow(new)
}
}
unlockSlow方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
fatal("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
// 如果不饥饿,还要进一步判断需不需要唤醒waiter
old := new
for {
// 如果等待队列为空,或者锁已经被获取,或者有醒着的线程去尝试获取锁,或者线程处于饥饿
// 直接返回即可,因为上述情况都不需要这个线程去唤醒waiter
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 唤醒一个waiter
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
// 如果饥饿(说明有饥饿的waiter),那么一定需要由该线程赖唤醒waiter,让他去走获取锁的流程
// 注意此时mutexLocked=0,但由于mutexStarving=1,所以新来的线程不会去获取到锁
runtime_Semrelease(&m.sema, true, 1)
}
}
sync.RWMutex
sync.RWMutex综合了写优先和非写优先锁:
- 避免writer饿死:当writer来尝试获取锁的时候,在其后面来的reader都得阻塞。写优先核心是通过
readerCount这个原子变量实现的 - 避免reader饿死:当writer释放锁时,在等待的reader马上获取到锁,即使当前还有其他的writer在等待。然后writer才能去竞争锁,继而阻塞后来的reader
RWMutex结构体:
1
2
3
4
5
6
7
type RWMutex struct {
w Mutex // writer互斥
writerSem uint32 // 写阻塞队列
readerSem uint32 // 读阻塞队列
readerCount atomic.Int32 // 所有reader的数量,负数表示有writer在等,优先让writer先获取锁
readerWait atomic.Int32 // 在等待写锁释放的reader数量
}
Lock方法:
1
2
3
4
5
6
7
8
9
10
11
12
func (rw *RWMutex) Lock() {
...
// 与其他writer互斥
rw.w.Lock()
// 通知其他reader现在有writer,禁止新的reader获取锁
r := rw.readerCount.Add(-rwmutexMaxReaders) + rwmutexMaxReaders
// 阻塞等待当前已经获取锁的读者完成
if r != 0 && rw.readerWait.Add(r) != 0 {
runtime_SemacquireRWMutex(&rw.writerSem, false, 0)
}
...
}
Unlock方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
func (rw *RWMutex) Unlock() {
...
// 通知其他reader现在没有writer
r := rw.readerCount.Add(rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
fatal("sync: Unlock of unlocked RWMutex")
}
// 唤醒所有reader
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 唤醒其他的writer
rw.w.Unlock()
...
}
RLock方法:
1
2
3
4
5
6
7
8
9
func (rw *RWMutex) RLock() {
...
// 加入一个reader
if rw.readerCount.Add(1) < 0 {
// 现在有writer,reader直接阻塞不去与writer竞争
runtime_SemacquireRWMutexR(&rw.readerSem, false, 0)
}
...
}
RUnlock方法:
1
2
3
4
5
6
7
8
9
func (rw *RWMutex) RUnlock() {
...
// 减少一个reader
if r := rw.readerCount.Add(-1); r < 0 {
// readerCount<0,说明有writer在等待,要进一步唤醒writer
rw.rUnlockSlow(r)
}
...
}
rUnlockSlow方法:
1
2
3
4
5
6
7
func (rw *RWMutex) rUnlockSlow(r int32) {
...
// 最后一个释放锁的reader负责唤醒writer
if rw.readerWait.Add(-1) == 0 {
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
sync.Map
sync.Map是线程安全版本的原生map。sync.Map通过空间换时间的方式,使用 read 和 dirty 两个 map 来进行读写分离,降低锁时间来提高效率。一下两种使用场景下,sync.Map并发效率往往比map+RWMutex更高
- append-only类型的cache:只写一次,读多次
- 多个协程读写key的集合不重叠,比如协程1经常读写k1,k2,协程2读写k3,k4
结构体定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 当key对应的值为expunged,说明这个key只在read中存在,在dirty中不存在
var expunged = new(any)
type entry struct {
p atomic.Pointer[any]
}
type Map struct {
mu Mutex
// dirty的子集(dirty为空除外),即除了expunged以外,dirty中存在的key,read可能没有
read atomic.Pointer[readOnly]
// 存了所有的key,当未命中read数次,就会将整个dirty同步到read中
dirty map[any]*entry
misses int
}
我们首先跟原生map对齐,先关注Store、Load、Delete三个方法
Store方法是用Swap方法实现的,直接看Swap,存入value,返回旧值(如果有的话,用loaded来指示):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
func (m *Map) Swap(key, value any) (previous any, loaded bool) {
read := m.loadReadOnly()
if e, ok := read.m[key]; ok {
// 命中read,尝试trySwap设置新值
// 如果trySwap返回false表明这个key已经被删了,得将key加入dirty
if v, ok := e.trySwap(&value); ok {
if v == nil {
return nil, false
}
return *v, true
}
}
// 互斥
m.mu.Lock()
read = m.loadReadOnly()
if e, ok := read.m[key]; ok {
// 命中read,并且为expunged的话,说明这个key之前被删掉了,要把key添加到dirty中
if e.unexpungeLocked() {
m.dirty[key] = e
}
// 设置新value
if v := e.swapLocked(&value); v != nil {
loaded = true
previous = *v
}
} else if e, ok := m.dirty[key]; ok {
// 未命中read,但dirty有这个key,说明是上一次dirty到read之后才设进来的key
// 直接设新value即可
if v := e.swapLocked(&value); v != nil {
loaded = true
previous = *v
}
} else {
// 未命中read,并且dirty也没有这个key,说明是新来的key
if !read.amended {
m.dirtyLocked()
m.read.Store(&readOnly{m: read.m, amended: true})
}
// 将key添加到dirty中
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
return previous, loaded
}
func (e *entry) trySwap(i *any) (*any, bool) {
for {
// 如果entry的value不存在,返回
p := e.p.Load()
if p == expunged {
return nil, false
}
// CAS设置entry的value
if e.p.CompareAndSwap(p, i) {
return p, true
}
}
}
// 初始化dirty为m.read的复制,除了值为nil的key
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read := m.loadReadOnly()
m.dirty = make(map[any]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
// 将值为nil的key设置为expunged
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := e.p.Load()
for p == nil {
if e.p.CompareAndSwap(nil, expunged) {
return true
}
p = e.p.Load()
}
return p == expunged
}
Load方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
func (m *Map) Load(key any) (value any, ok bool) {
read := m.loadReadOnly()
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read = m.loadReadOnly()
e, ok = read.m[key]
if !ok && read.amended {
// 未命中read,直接读dirty,并且视为miss
e, ok = m.dirty[key]
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
// 当read miss次数达到dirty的长度,直接将其整个同步到read中,提高并发读效率
m.read.Store(&readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
Delete方法直接调用的是LoadAndDelete:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
func (m *Map) LoadAndDelete(key any) (value any, loaded bool) {
read := m.loadReadOnly()
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read = m.loadReadOnly()
e, ok = read.m[key]
if !ok && read.amended {
// 未命中read,直接删除dirty中的key
e, ok = m.dirty[key]
delete(m.dirty, key)
m.missLocked()
}
m.mu.Unlock()
}
if ok {
// 将value置空
return e.delete()
}
return nil, false
}
综上,可以总结出以下几种常见情况:
- 当key命中read的时候,直接用CAS/Load原子操作完成对value的读、写、删。其中删除需要对value置空而不是从map中删除key是为了将删转换为写操作,以便用CAS完成,属于空间换时间的做法
- 当读key未命中read数次,将dirty同步到read,dirty置空,等下次写key未命中的时候重新初始化dirty
- 当写key未命中read(expunged也属于未命中),说明key被删除了,需要往dirty里写入
支持泛型的sync.Map
官方提供的sync.Map并不支持泛型,所以可以自己封装一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
type SyncMap[K comparable, V any] struct {
m *sync.Map
}
func NewSyncMap[K comparable, V any]() SyncMap[K, V] {
return SyncMap[K, V]{
m: &sync.Map{},
}
}
func (m SyncMap[K, V]) Store(key K, value V) {
m.m.Store(key, value)
}
func (m SyncMap[K, V]) Load(key K) (value V, ok bool) {
v, ok := m.m.Load(key)
if !ok || v == nil {
return
}
return v.(V), true
}
func (m SyncMap[K, V]) Delete(key K) {
m.m.Delete(key)
}
func (m SyncMap[K, V]) Range(f func(K, V) bool) {
m.m.Range(func(k, v any) bool {
if k == nil && v == nil {
return f(*new(K), *new(V))
} else if k == nil {
return f(*new(K), v.(V))
} else if v == nil {
return f(k.(K), *new(V))
}
return f(k.(K), v.(V))
})
}
func (m SyncMap[K, V]) LoadAndDelete(key K) (value V, loaded bool) {
v, loaded := m.m.LoadAndDelete(key)
if !loaded || v == nil {
return
}
return v.(V), true
}
func (m SyncMap[K, V]) LoadOrStore(key K, value V) (actual V, loaded bool) {
v, loaded := m.m.LoadOrStore(key, value)
if v == nil {
return
}
return v.(V), loaded
}
func (m SyncMap[K, V]) CompareAndSwap(key K, old, new V) bool {
return m.m.CompareAndSwap(key, old, new)
}
func (m SyncMap[K, V]) CompareAndDelete(key K, old V) (deleted bool) {
return m.m.CompareAndDelete(key, old)
}
sync.WaitGroup
sync.WaitGroup也是非常常见的同步工具,有两种常见用法:
一个协程用于等待一组协程全部执行完成
1 2 3 4 5 6 7
for ... { wg.Add(1) go func() { defer wg.Done() } } wg.Wait()
多个协程等待一个协程执行完成,比如在singleflight的实现里就用到了
1 2 3 4 5 6 7
wg.Add(1) for ... { go func() { wg.Wait } } wg.Done()
结构体定义:
1
2
3
4
5
6
7
8
type WaitGroup struct {
noCopy noCopy
// 高32位是计数器,低32位是阻塞队列大小
state atomic.Uint64
// 阻塞队列
sema uint32
}
Add方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
func (wg *WaitGroup) Add(delta int) {
...
state := wg.state.Add(uint64(delta) << 32)
v := int32(state >> 32)
w := uint32(state)
...
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
if v > 0 || w == 0 {
// 计数器>0或者没有waiter都可以直接返回
return
}
if wg.state.Load() != state {
// 由于计数器减为0的这个协程需要唤醒所有waiter,它必须执行两步操作:
// 1.获取waiter数量 2.唤醒这些waiter
// 由于1和2之间存在「新增waiter」的风险,导致无法正确唤醒所有waiter
// 因此这里做了一个sanity check检查是否有并发的Add和Wait
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 置waiter数量为0,避免其他协程重复唤醒同一批waiter
wg.state.Store(0)
// 唤醒waiter
for ; w != 0; w-- {
runtime_Semrelease(&wg.sema, false, 0)
}
}
Wait方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func (wg *WaitGroup) Wait() {
...
for {
state := wg.state.Load()
v := int32(state >> 32)
w := uint32(state)
if v == 0 {
...
return
}
// 增加waiter
if wg.state.CompareAndSwap(state, state+1) {
...
runtime_Semacquire(&wg.sema)
// sanity check检查是否有并发的Add和Wait
if wg.state.Load() != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
...
return
}
}
}
sync.Pool
sync.Pool一般是为了优化内存的使用,通过缓存对象来避免频繁地创建销毁对象,降低GC压力。
结构体定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
type Pool struct {
noCopy noCopy
// per-P的poolLocal数组,下标为Pid
local unsafe.Pointer
// local的大小
localSize uintptr
// 上次GC回收的local
victim unsafe.Pointer
// victim的大小
victimSize uintptr
// 对象创建工厂,当Pool没有缓存的对象,会调用New来创建对象
New func() any
}
type poolLocalInternal struct {
private any // 避免每次都访问shared共享队列,类似于p.runnext
shared poolChain // 无锁循环队列
}
type poolLocal struct {
poolLocalInternal
// 将poolLocal填充对齐到缓存行大小,避免多个P之间存在伪共享问题
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
var (
// 保护allPools的锁
allPoolsMu Mutex
// 保存了当前在使用的Pool
allPools []*Pool
// 保存了当前victim不为空的Pool,这些Pool的victim会在下一轮GC被回收
oldPools []*Pool
)
Put方法,将对象放入Pool,以在未来复用缓存的对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
func (p *Pool) Put(x any) {
if x == nil {
return
}
...
// 绑定G-M-P避免抢占,获取当前P的poolLocal
l, _ := p.pin()
if l.private == nil {
// 优先将对象放入poolLocal.private
l.private = x
} else {
// 将对象插入队列头
l.shared.pushHead(x)
}
// 解绑
runtime_procUnpin()
...
}
pin方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
func (p *Pool) pin() (*poolLocal, int) {
// 将G和当前M绑定防止抢占,返回Pid
pid := runtime_procPin()
// 读取localSize和local
s := runtime_LoadAcquintptr(&p.localSize)
l := p.local
if uintptr(pid) < s {
// fast-path: 如果Pid在local数组中,直接返回即可
return indexLocal(l, pid), pid
}
// slow-pat: P的数量改变了,需要进一步处理
return p.pinSlow()
}
func (p *Pool) pinSlow() (*poolLocal, int) {
// 加全局锁(加锁前必须unpin,因为如果加锁失败了就会进入阻塞,此时p应该可以被抢占)
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
// 成功获取到锁,重新pin,并再次尝试走fast-path
pid := runtime_procPin()
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
// local为空表明当前Pool还没加入到全局Pool数组中
if p.local == nil {
allPools = append(allPools, p)
}
// 分配新的local,大小为GOMAXPROCS
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0]))
runtime_StoreReluintptr(&p.localSize, uintptr(size))
return &local[pid], pid
}
Get方法,优先从缓存中取出对象,当缓存为空,会自动调用New工厂方法创建对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
func (p *Pool) Get() any {
...
// 绑定G-M-P避免抢占,获取当前P的poolLocal
l, pid := p.pin()
// 优先从private取缓存对象
x := l.private
l.private = nil
if x == nil {
// 考虑到时间局部性,与Put的将对象存入队头对应,Get从队头获取对象,提高cache命中率
x, _ = l.shared.popHead()
if x == nil {
// poolLocal为空,进一步处理
x = p.getSlow(pid)
}
}
runtime_procUnpin()
...
if x == nil && p.New != nil {
// 整个Pool都没有缓存对象,用New创建
x = p.New()
}
return x
}
getSlow方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
func (p *Pool) getSlow(pid int) any {
size := runtime_LoadAcquintptr(&p.localSize)
locals := p.local
// 尝试从其他P的缓存队列中获取对象
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 从上一轮的poolLocal中获取,即希望即将要被回收victim中获取对象
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 很明显victim也是空,将victimSize置0
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
面向用户的几个方法都过了一遍,Put和Get方法很明显只是单纯的存取对象,但Pool的亮点就在于自动识别那些对象需要回收,将GC负载变得更为平滑,那么Pool是如何做到的呢。
答案就是poolCleanUp方法,这个方法在GC开始STW的时候被调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
func poolCleanup() {
// 让上一次进入victim的缓存全部GC掉
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// 将当前缓存进入victim
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// 最后就是oldPools可能会被回收掉
oldPools, allPools = allPools, nil
}
这个函数在init中被注册到runtime中作为回调函数,在GC开始时被调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
// runtime/mgc.go
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}
func clearpools() {
...
// clear sync.Pools
if poolcleanup != nil {
poolcleanup()
}
...
}
func gcStart(trigger gcTrigger) {
...
// clearpools before we start the GC. If we wait they memory will not be
// reclaimed until the next GC cycle.
clearpools()
...
}
综上,sync.Pool借助GC以及GC开始时的回调函数,为我们提供了:
- 缓存对象的能力,避免频繁创建对象
- 自动回收缓存池对象的能力
其实我们也能很容易实现自己的对象缓存池,但是sync.Pool可以精确地控制在GC开始时回收缓存,而我们并不知道GC什么时候开始,需要更加复杂的手段去实现。
但是Pool的使用也有很多需要注意的地方,参考这篇博客,看一个具体场景:服务端接收请求,并且创建结构体去存储请求的数据,然后执行业务,为了避免大量请求创建销毁结构体,使用Pool进行缓存。执行的业务中包含了两个异步操作:
- 异步发送请求数据到kafka
- 异步调用下游服务
在该处理请求的handler返回前将对象归还到Pool中。
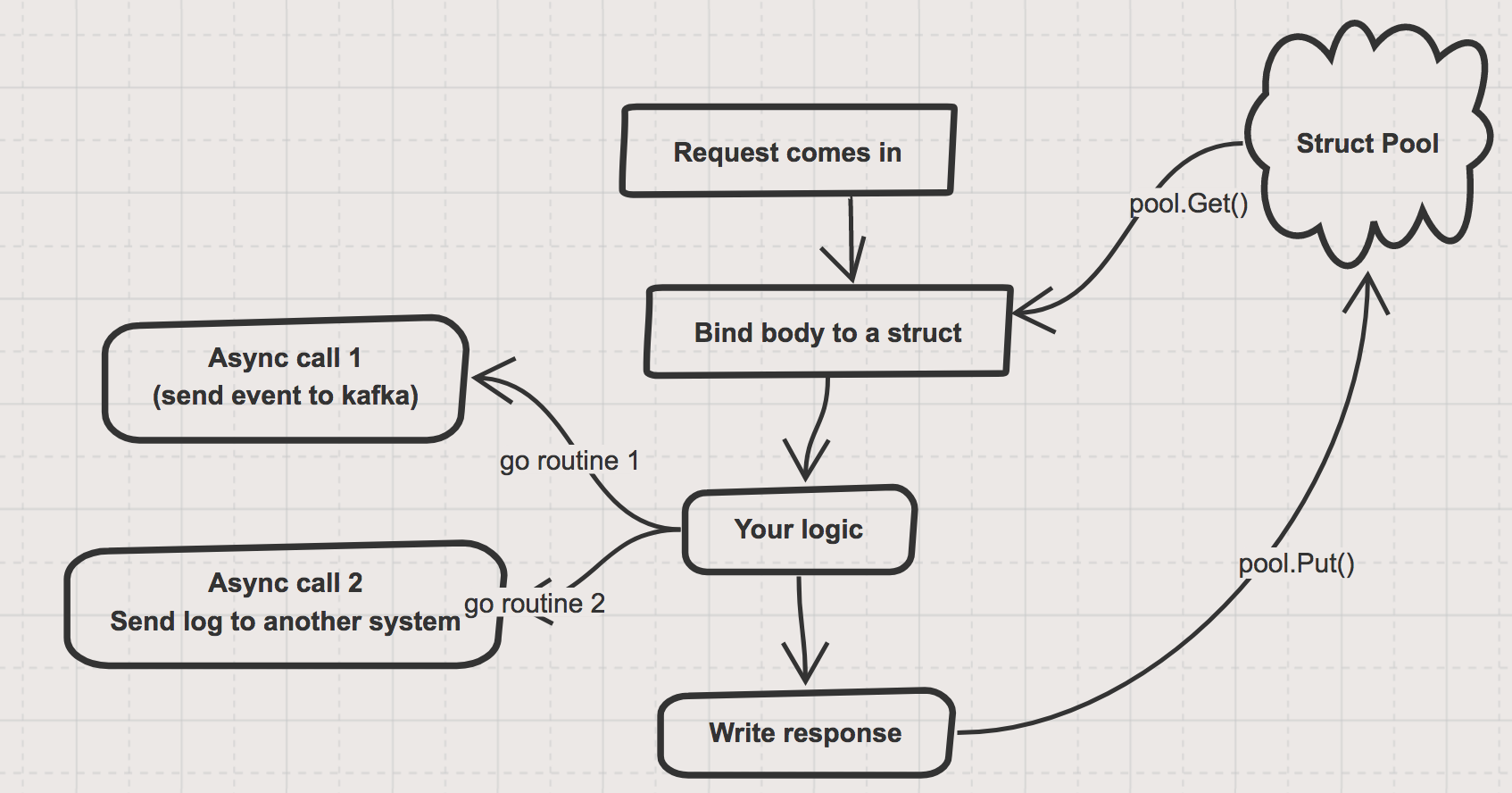
但此时就引发了问题:业务逻辑是异步执行的,当handler函数返回后,业务逻辑还在异步地执行,可能还会去读之前从Pool中拿出来的请求体。如果此时有其他协程复用了这个请求体并且改变了里面的数据,那么就出问题了。
一个可能的解决方案是给对象加上一个引用计数,开启新协程之前引用+1,协程返回前-1,当引用变成0后才将其归还到Pool中。思路看上去没问题,具体实现可以参考那篇博客中在最后给出的代码。下面给出我的实现(未经测试)。
方法命名上我使用的是WaitGroup那样的命名:Add和Done,具体见注释。并且规范了缓存池的使用:
RefPool用于一条业务处理逻辑,多协程访问同一个缓存池对象时,通过增加引用计数,当该业务线所有协程都完成时,才将对象放回缓存池中,以免其他业务线同时修改该对象。RefPool的使用方法与WaitGroup有相似之处:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// 常规使用场景 x := pool.Get() defer pool.Done(x) // 主协程使用完毕 for ... { pool.Add(x) go func() { defer pool.Done(x) // 子协程使用完毕 } } // 其他场景:从缓存池拿出对象后不打算再放入缓存池中 x := pool.Get() ... pool.Untrack(x)
不能Done、Add、Untrack一个不是由Get获取的对象
以下是具体实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
type RefPool struct {
pool sync.Pool
counter sync.Map
f func() any
}
func NewRefPool(f func() any) *RefPool {
p := &RefPool{
pool: sync.Pool{},
}
p.pool.New = f
return p
}
// 从对象池获取一个对象,引用数初始化为1
func (p *RefPool) Get() any {
x := p.pool.Get()
if x == nil {
return nil
}
_, ok := p.counter.Load(x)
// sanity check
if ok {
panic("inconsistency")
}
c := &atomic.Int32{}
c.Add(1)
p.counter.Store(x, c)
return x
}
// 增加对象的引用数
func (p *RefPool) Add(x any) {
c, ok := p.counter.Load(x)
if !ok {
panic("untracked object")
}
c.(*atomic.Int32).Add(1)
}
// 对象的引用数-1,如果引用数减为0,则将对象放回对象池
func (p *RefPool) Done(x any) {
c, ok := p.counter.Load(x)
if !ok {
panic("untracked object")
}
if v := c.(*atomic.Int32).Add(-1); v == 0 {
if deleted := p.counter.CompareAndDelete(x, c); !deleted {
// sanity check
panic("inconsistency")
}
p.pool.Put(x)
}
}
// 不再跟踪该对象,将不再进入缓存池,同时也不再维护引用计数
func (p *RefPool) Untrack(x any) {
c, ok := p.counter.Load(x)
if !ok {
panic("untracked object")
}
if deleted := p.counter.CompareAndDelete(x, c); !deleted {
// sanity check
panic("inconsistency")
}
}
可改进之处:
- 可以Add、Done、Untrack一个未经Get的对象,使用起来可以更加灵活
- 更进一步地,可以将对象封装为Ref接口,增加Val、Inc、Dec、Untrack方法,也就是将计数的维护委托给对象自身,省去维护以及并发访问RefPool.counter,最终RefPool只保留Get方法用于获取新对象
参考
Russ’s discussion about reentrant lock