OS
复习用
软中断
中断请求的处理程序应该要短且快,因为中断处理程序要求关中断(不接受新的中断请求),如果中断处理程序执行时间过长,可能在还未执行完中断处理程序前,会丢失当前其他设备的中断请求。
为了解决由于中断处理时间过长,导致新来的中断丢失,将中断分成两个部分:
- 硬中断:先关中断,处理跟硬件紧密相关或者时间敏感的事情
- 软中断:由内核触发,完成该中断剩余的耗时工作
其中硬中断直接抢占cpu,而软中断有专门的内核线程ksoftirqd处理,由操作系统调度执行。
软中断不只是设备中断的下半部分,一些内核自定义事件也属于软中断,比如内核调度等、RCU 锁。
linux上/proc/softirqs记录当前各类型软中断个数,如果NET_RX个数变化过快,说明很多网络包打进来,可以用tcpdump抓包分析,如果发现是异常流量,可以加防火墙,如果是正常流量,需要考虑升级硬件。
进程的状态
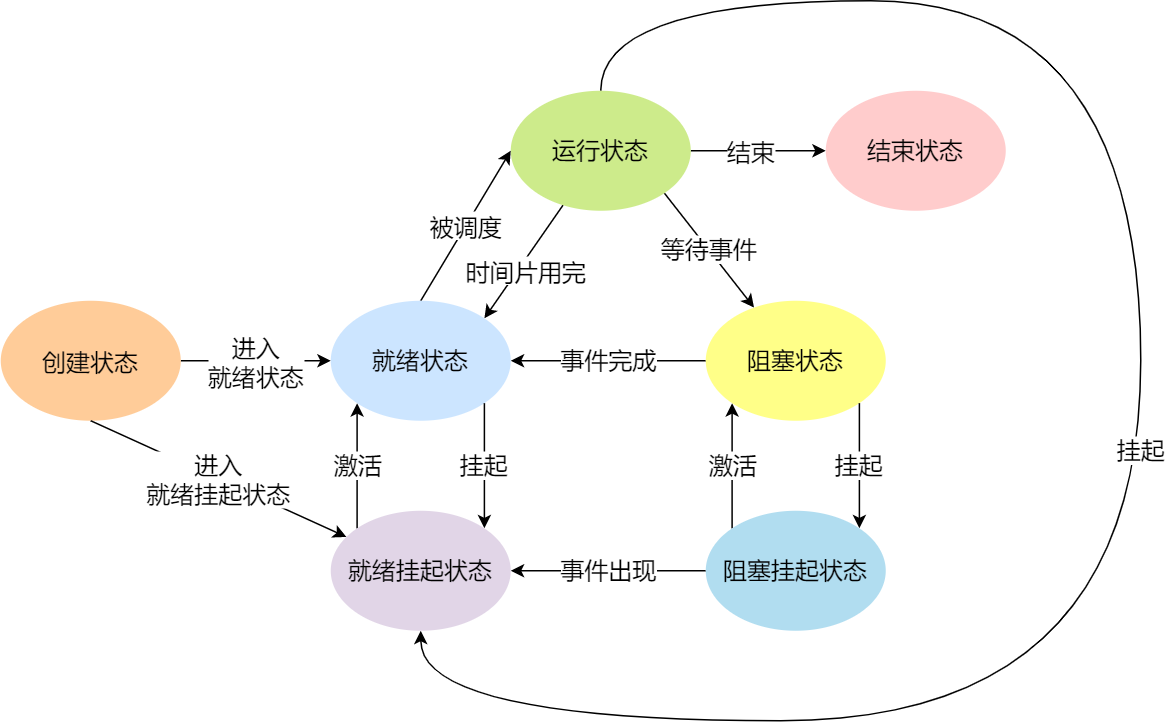
挂起态:处于阻塞状态的进程,进程可能会占用着物理内存空间,那么,就需要一个新的状态,来描述进程没有占用实际的物理内存空间的情况,这个状态就是挂起状态。(sleep或者ctrl+z)
进程和线程比较
- 创建:
- 进程是资源(内存、文件等)分配的基本单位,线程是调度的基本单位
- 进程创建涉及内存管理、文件管理等操作。而线程独享的资源只有寄存器和栈,对于内存和文件只需要共享即可
- 线程销毁更快,因为相对要释放的资源更少
- 切换调度
- 同一进程的线程切换更快,因为线程共享进程的地址空间,内存管理单元不涉及切换过程,不需要切换页表,不用冲刷TLB,要切换的上下文信息也少了很多
- 数据传递
- 同一进程的线程传递数据更快,由于共享内存、文件等资源,那么线程传递数据不需要经过内核,经过内核意味着需要切换到系统栈上执行,相当于切换上下文,并且系统调用由于不相信外界用户代码,会有额外的检查工作
死锁
条件:
- 互斥
- 资源不可剥夺
- 循环等待
- 占有并等待
切换内核态开销大的原因
每个进程都会有两个栈,一个内核态栈和一个用户态栈。当中断执行时就会由用户态栈转向内核态栈,系统调用时需要进行栈的切换,而且内核代码对用户不信任,需要进行额外的检查。系统调用的返回过程有很多额外工作,比如检查是否需要调度等。
虚拟内存
进程访问一个虚拟地址时,CPU芯片中的内存管理单元MMU会将其映射为物理地址,最终拿着这个物理地址去访问内存。而虚拟地址物理地址的映射方式主要有分段和分页两种。
分段:由程序员将虚拟内存划分为一个个段,虚拟地址划分为段号和段内偏移量,段号用于在段表中查询段的物理基地址、段大小、特权等级等。段基地址+段内偏移量就构成了物理地址。
分段存在的问题:
- 内存碎片:会有外部碎片。解决外部碎片是通过内存交换,也就是通过swap的方式实现了碎片整理,具体是将在用的内存先交换到硬盘上,然后再装载到内存当中,但是不是装载回原来的位置,而是紧邻上一片正在使用的内存。
- 内存交换率低:由于涉及到读写硬盘,因此swap的效率低是必然的。
综上,分段由于经常出现外部内存碎片,经常触发swap整理碎片,导致整个机器的卡顿。
分页:由操作系统将虚拟内存划分成一个个大小相同的页,虚拟地址划分为页号和页内偏移量,页号用于在页表中查询页的物理页号,拼接上页内偏移量就构成了物理地址。
分页的特点:消除了外部碎片,并且通过限制页的大小,限制了每次swap也只有一个或几个页,提高swap的效率。但是由于操作系统给进程分配物理内存是以页为单位的,当一个页没有全部使用到的话,会出现内部碎片,但页大小比较小,因此内部碎片的大小也会控制在一定范围内。
多级页表:由于一个虚拟地址必须通过查询页表来找到对应的物理页,而32位机器+4KB页大小的环境下,一个进程的页表占据4MB大小,这样纯属是一种浪费。因此引入二级页表,让一级页表长居内存,而二级页表在需要的时候再加载到内存,由于程序的空间局部性,最好的情况下内存只需要为进程保留一级页表和一页的二级页表。
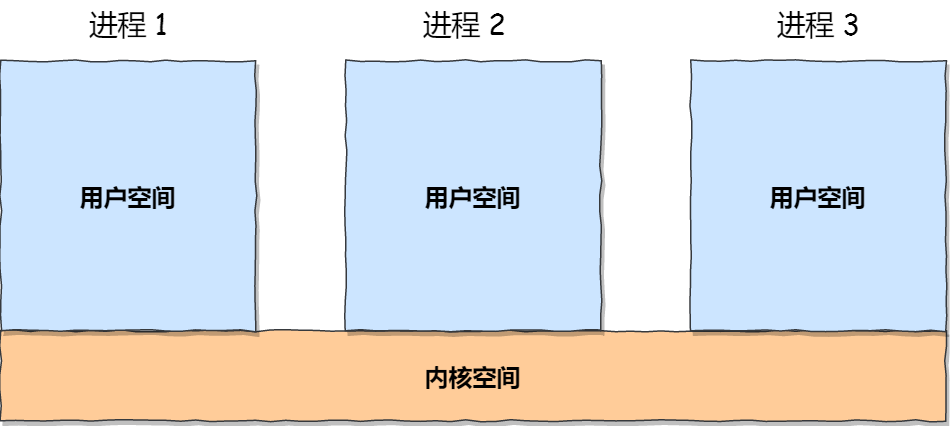
linux内存布局
每个进程的虚拟内存空间划分为用户空间和内核空间,所有进程的内核空间实际上映射的是同一块物理内存:
下面是用户空间的具体布局:
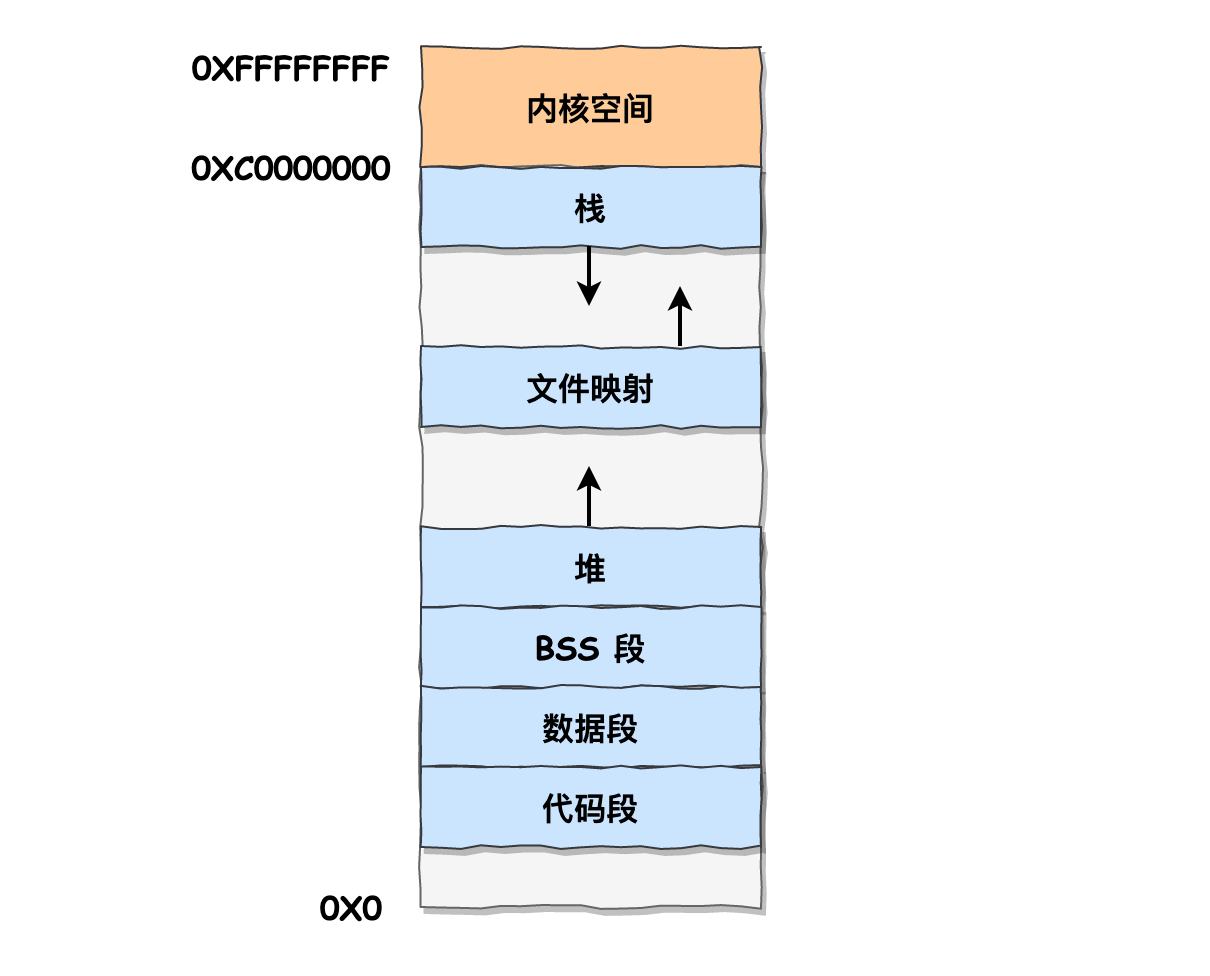
其中文件映射段的内存和堆内存一样都是动态分配的,比如使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
malloc分配内存的原理
malloc可能会使用brk或者mmap这两个系统调用来向操作系统申请内存:当分配内存小于128KB则用brk,大于128KB则用mmap。brk的内存在free之后会归还内存池,不会归还给操作系统,而mmap的内存free之后直接归还给操作系统。因此,如果全部使用mmap来分配内存,那么每次分配内存都触发系统调用,并且每次都触发缺页中断,效率非常低。
OOM原理
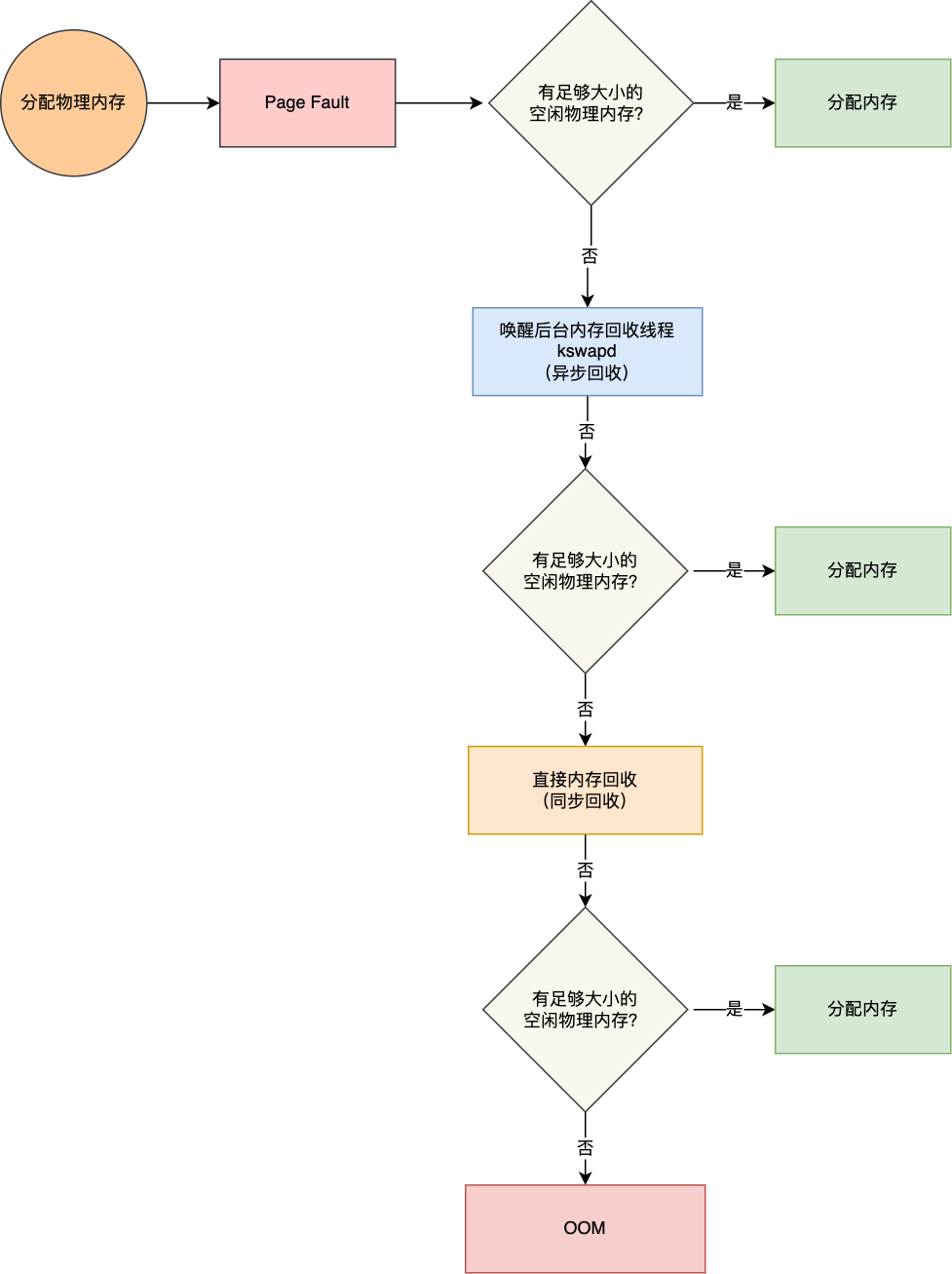
- 触发异步回收,不阻塞进程执行
- 触发同步回收,阻塞进程执行
- OOM
可以被回收的内存分为文件页和匿名页,对于脏页,会触发IO写回硬盘,否则可以直接释放。对于匿名页(堆、栈等用户程序使用到的内存)则通过swap机制换出到硬盘。因为触发磁盘IO,降低系统运行效率,看起来就是发生卡顿。
如果没有空闲文件页和匿名页,并且也没有未分配的物理内存,就会触发OOM,根据算法选择占用物理内存较高的进程,然后将其杀死,以便释放内存资源,直到有足够的内存进行分配。
如何保护一个进程不被OOM杀掉:OOM killer选择被杀程序的时候通过计算一个分数来决定,分数越高越优先被杀
1
2
3
4
5
// points 代表打分的结果
// process_pages 代表进程已经使用的物理内存页面数
// oom_score_adj 代表 OOM 校准值
// totalpages 代表系统总的可用页面数
points = process_pages + oom_score_adj*totalpages/1000
oom_score_adj可设置的范围为[-1000, 1000],默认为0,只与进程占用的物理内存页数相关。可以通过设置oom_score_adj为 -1000,降低该进程被 OOM 杀死的概率。一般是特别重要的系统服务才会做这样的配置。
linux和mysql的缓存
- Linux(Page Cache):应用程序读取文件的数据的时候(比如目录缓存、索引缓存、页缓存),会缓存到内存中的Page Cache
- MySQL(Buffer Pool):当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
高可用系统考虑那些方面
- 负载均衡:应用部署在多台服务器上进行负载均衡
- 动静分离:CDN缓存用户静态资源(分布式资源分发,将静态资源缓分发到最接近用户的节点上)、nginx缓存源服务器的静态资源
- 连接复用:数据库连接池、redis连接池、线程池等
- 读多写少:redis缓存读多写少的数据
- 异步写入:使用消息队列存储数据库写入请求,实现流量削峰
- 分库分表:来到数据库本身的性能问题上,使用分库,扛住更高的并发量,使用分表,使得每个表的数据量更少,提高单表查询性能
- 读写分离:不便于分表的情况下,如果数据库是读多写少,使用主从模式进行读写分离
- 服务降级:数据库实在扛不住了,可以暂时容忍数据不一致的话,可以只读本地缓存、只读分布式缓存、只读默认降级数据
进程通信方式和区别
管道:所谓的管道,就是内核里面的一串缓存。
数据无格式、缓存大小受限、只能先进先出、对外表现为无缓存队列(读写必须配合)、必须经过内核
- 匿名管道,只能通过 fork 来复制父进程 fd 文件描述符,来达到通信的目的。
- 命名管道,提前创建了一个类型为管道的设备文件,在进程里只要使用这个设备文件,就可以相互通信。
消息队列:消息队列是保存在内核中的消息链表,消息体是用户自定义的数据类型(解决管道数据流无格式),发送消息到消息队列后可以立刻返回(解决管道必须读写配合的限制),读出消息后消息从队列删除。
通信不及时、消息大小和队列长度受限、必须经过内核
共享内存+信号量:共享内存通过虚拟内存映射到同一块物理内存实现,不需要经过内核,一个进程写了之后另一个进程马上能看到,不需要拷贝,不过需要额外的同步机制。信号量实现读写互斥/同步机制
信号:进程间唯一的异步通信机制,因为可以在任何时候发送信号给某一进程。进程可以自定义信号处理函数,但有两种信号无法自定义,
SIGKILL(杀死)和SIGSTOP(挂起)socket:进程间唯一跨主机通信机制,可以指定TCP或者UDP
- TCP:服务端
socket,bind,listen,accept(返回fd),客户端socket,connect(返回fd),然后就可以对fd进行read(fd),write(fd)传输数据 - UDP:服务端
socket,bind,客户端socket,bind,然后就可以sendto(传入ip和port),recvfrom(传入ip和port)传输数据 - 本地:不用绑定ip和端口,只需要绑定一个本地文件
- TCP:服务端
零拷贝(小文件网络传输)
零拷贝描述的是传输本地文件到网络(相当于一个文件的内容写入另一个文件)
下述的内核缓冲区其实就是page cache。
read+write:4次数据拷贝,4次上下文切换(因为调用一次就2次切换用户/内核态)
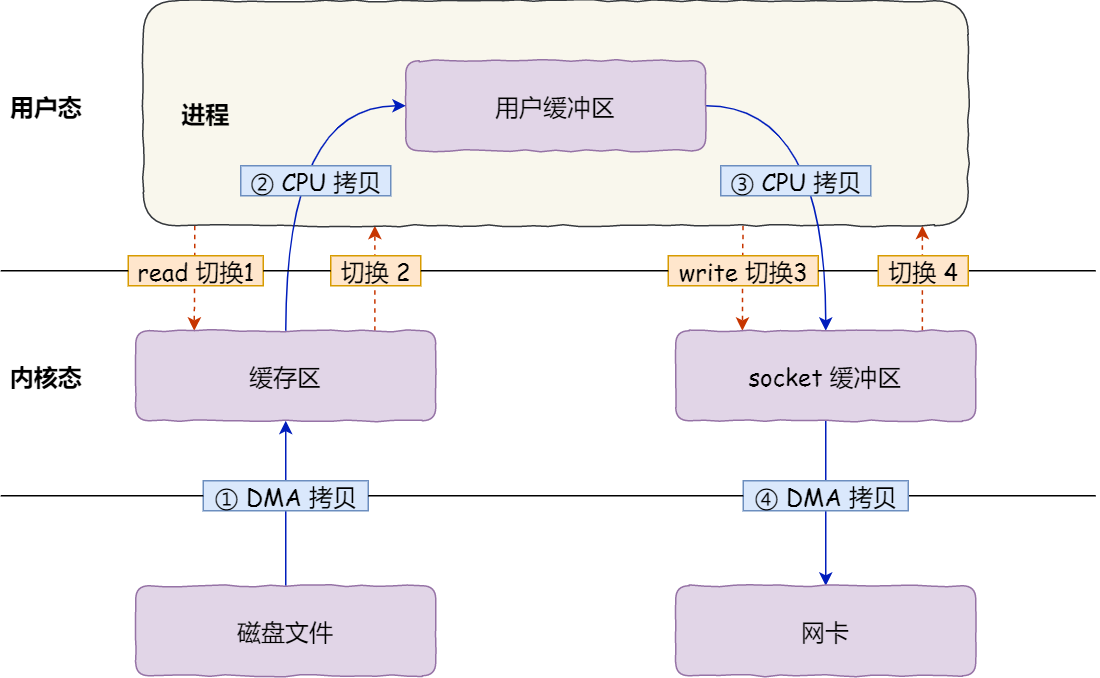
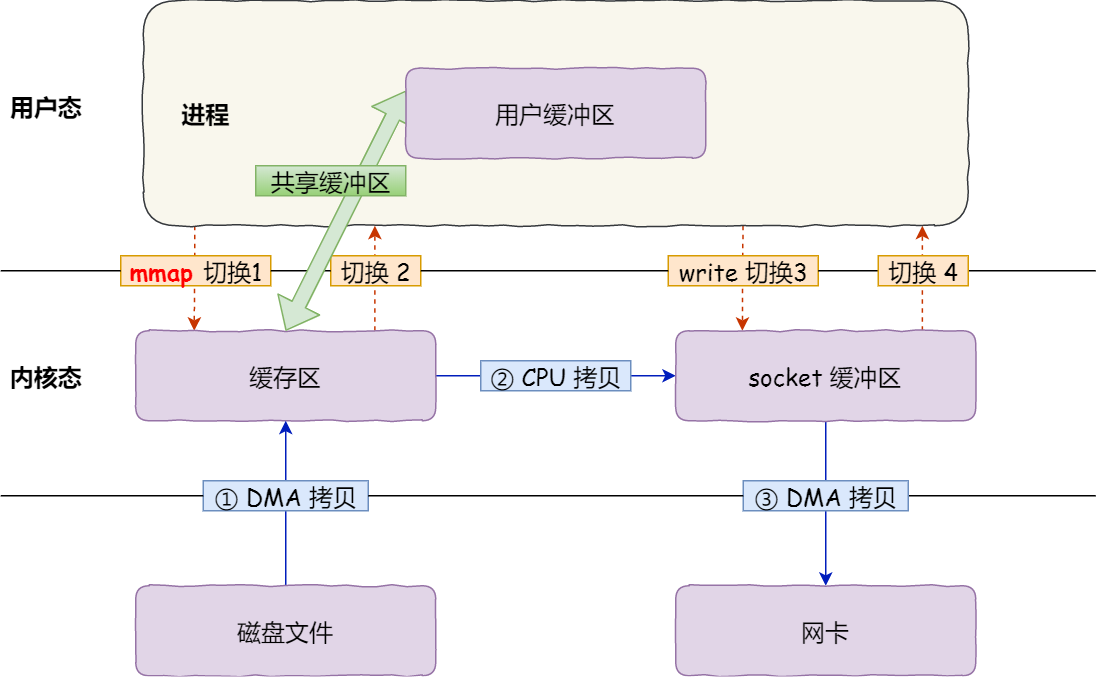
mmap+write:mmap将用户缓冲区映射为内核缓冲区,减少一次数据拷贝,一共3次数据拷贝,4次上下文切换
sendfile:只有sendfile一个系统调用,减少一次系统调用,另外将文件的内核缓冲区直接拷贝到socket缓冲区,减少一次数据拷贝(与mmap一样),一共3次数据拷贝,2次上下文切换
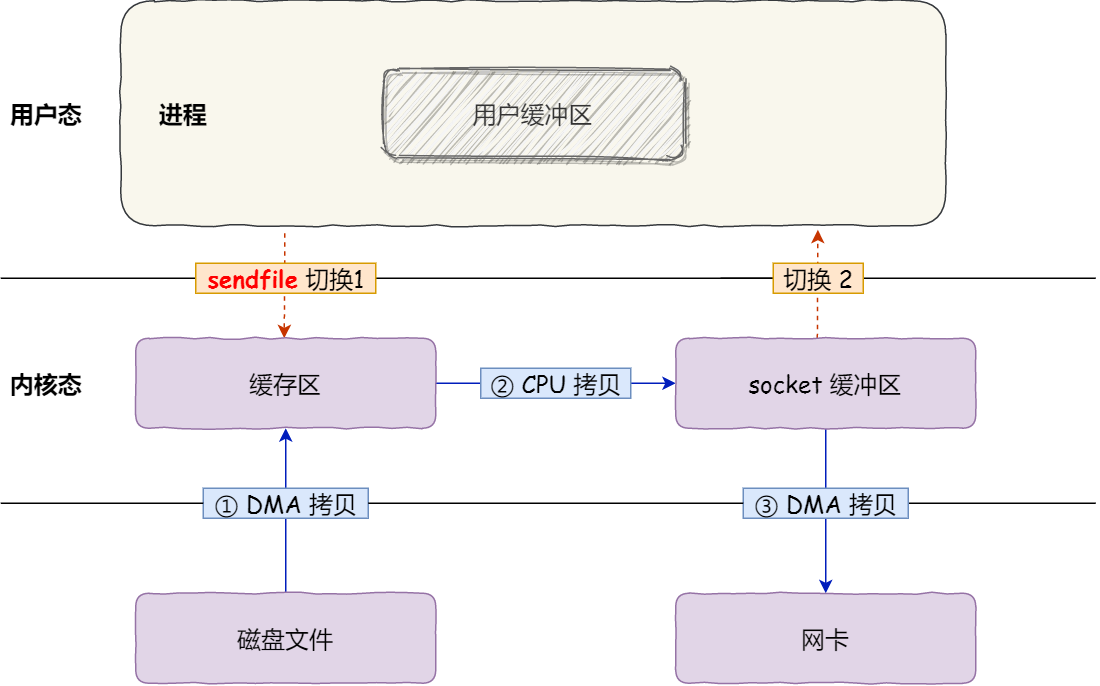
sendfile+支持SG-DMA的网卡:网卡的 SG-DMA 控制器直接将内核缓存中的数据拷贝到网卡的缓冲区里,不用再拷贝到内核的socket缓冲区,一共2次数据拷贝,2次上下文切换
零拷贝只适用于小文件,因为要把文件内容一次性拷贝到page cache,如果是大文件,那么就很容易造成大范围的缓存污染。
扩展:kafka中使用零拷贝向消费者发送消息:
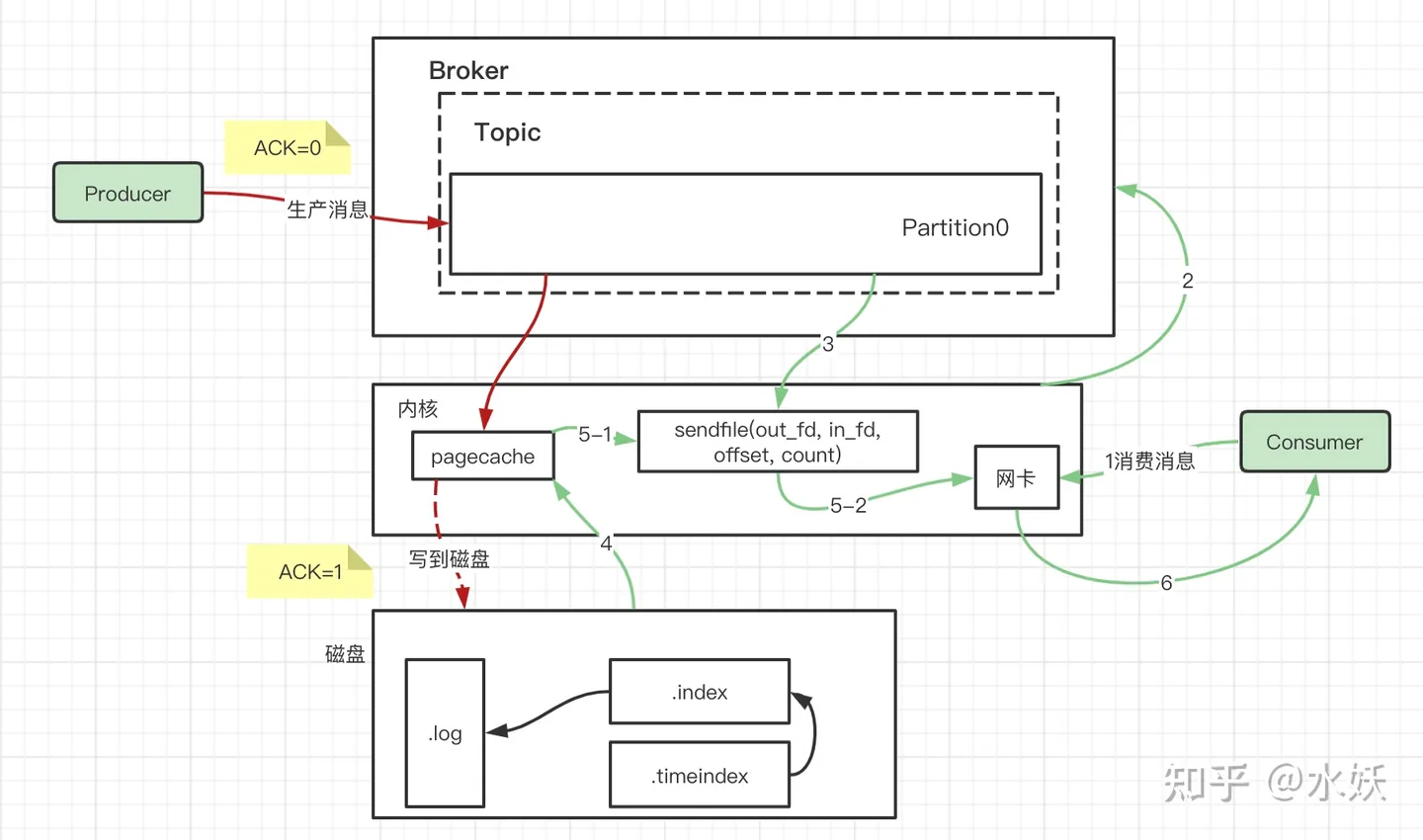
零拷贝深入解析
https://strikefreedom.top/archives/linux-io-stack-and-zero-copy
零拷贝场景
kafka - https://strikefreedom.top/archives/why-kafka-is-so-fast
go语言的零拷贝 - https://andypan.me/zh-hans/posts/2021/06/06/pipe-pool-for-splice-in-go/
大文件网络传输
read是同步阻塞+缓存IO的(缓存指的是page cache):系统调用read、数据从设备拷贝到page cache、从page cache拷贝到用户缓冲区、read返回。
使用异步IO+直接IO(绕过page cache直接读到用户内存):系统调用read并无阻塞地返回、数据从设备拷贝到用户缓冲区(异步)、通过信号通知读取成功。
缓存预读失效、污染
linux的PageCache:将LRU分为active和inactive两个队列,预读页和第一次访问的页会进入inactive,当访问第二次的时候才会进入active
mysql的BufferPool:将LRU分为young和old,预读页和第一次访问的页会进入young,当页的某次访问距离第一次访问超过1s时才会进入old
inode
Linux 每个文件分配两个数据结构:
- 索引节点inode:记录文件的元信息,包括文件大小、权限、创建/修改时间、在磁盘的位置等。inode是文件的唯一标识。inode也会占据硬盘空间
- 目录项dentry:记录文件的名字、索引节点指针、与其他目录项的层级关系。目录项不在硬盘存储,而是存在内存中
目录:目录也是一个文件,存储在硬盘,保存了子目录或者文件的信息。注意目录项不是目录,目录项可以表示目录也可以表示文件,是缓存在内存中的结构,避免每次寻找文件时都要访问磁盘上的目录、文件元信息等。
软链接和硬链接
硬链接是创建目录项让其inode指针指向同一个inode,因为每个文件系统的inode结构都不一样,所以硬链接很明显不能跨文件系统创建。当创建了硬链接,删除一个文件只有删除所有硬链接以及源文件的时候,文件才真正被删除。
软链接是创建新文件,文件内容是另一个文件的路径,软链接是可以跨文件系统创建的。当源文件删除,软链接还在,只不过打开软链接的时候会发现目标文件不存在。
五种IO模型
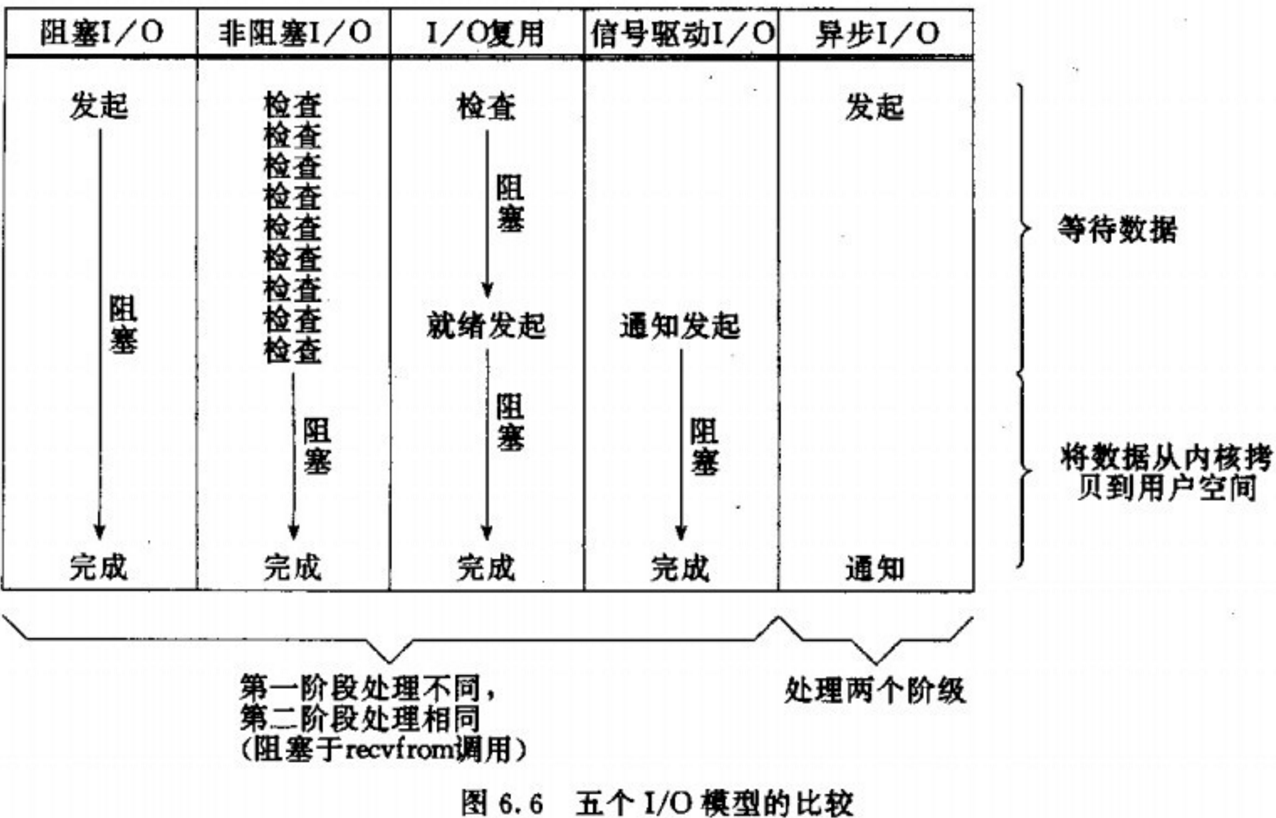
判定一个IO模型是同步还是异步,只需要看第二步的「从内核空间拷贝到用户空间」是否会阻塞当前进程,如果会阻塞则是同步,否则就是异步。因此只有最后一种IO模型真正支持异步。
比如在go的netpoll模型中,使用的是非阻塞+多路复用,通过非阻塞的epoll,借助GMP的能力实现用户态进行goroutine的调度,避免陷入内核态阻塞。
僵尸进程 / 孤儿进程
僵尸进程是已经终止但还没有被父进程回收的进程,特性如下:
- 父进程忙着干别的事情,一直没有wait/waitpid
- 僵尸进程在
ps命令中的状态是Z - 僵尸进程不消耗CPU,也不占用内存,因为不再执行代码,只占用少量页表项
- 僵尸进程本身已经结束,无法通过kill杀死
僵尸进程的危害:
- 占据大量页表项,OS对页表项有数量限制,页表项用完后系统无法创建新的进程,甚至无法执行命令
- 如果一个进程反复生成僵尸进程可以视为资源泄露,特别在嵌入式等内存受限的环境当中造成系统性能下降
解决方法:可以考虑重启父进程(成为新的进程),那么这些僵尸进程就会变成孤儿进程,被操作系统pid=1的init进程接管并清理,或者重启系统。然后修复代码,使其正确回收子进程避免让他们成为僵尸进程